Bitcoin On-Chain Exchange Metrics: The Good, The Bad, The Ugly
In the present work, we give insights into the importance of analyzing exchange activity, the processes of accurately tracking exchange addresses, and the caveats that come with exchange data.

Cryptocurrency exchanges are major driving forces in the digital assets market. It is where most trading happens and prices are made.
It is therefore important to track exchange activity on-chain, e.g. the bitcoin supply exchanges are holding at any given point in time, and the amount of BTC that is flowing in and out of exchange addresses. These data can give invaluable insights into Bitcoin liquidity, investor behaviour, and the supply-side of the market.
There is a general lack of understanding of the processes that go into tracking exchange wallets and, consequently, obtaining high-quality on-chain exchange data.
Here, we aim to increase transparency and understanding and shine some light on the challenges of producing exchange metrics. This explainer should give insights into the importance of looking at exchange activity, the processes of accurately tracking exchange addresses, and the caveats that can come with exchange data. We hope to significantly increase the understanding of this metric family and provide investors with general guidelines on how to properly read them and what to watch out for.
TL;DR
- Tracking exchange data is an imperfect process, as each exchange has unique wallet management practices and wallet addresses are dynamic and constantly changing.
- Individual data points such as a large inflow/outflow should be considered as preliminary in the first instance until verified. Glassnode opts for a conservative approach and aims to limit the reporting of false positives and provide the most accurate data possible.
- Data points can be considered increasingly reliable over time as exchange wallets transact and interact such that our heuristics and clustering algorithms enhance labeling and thus accuracy.
- Exchange metrics can historically change, either because heuristics assign addresses to an exchange cluster, or because verified exchange addresses are added manually.
The Good
The Bitcoin blockchain is an open ledger that allows us to analyze all transactions that have ever been made, and assess the number of coins any given address in the network is holding or moving.
To track exchange movements, we need to know which network addresses belong to an exchange. Those addresses can then be monitored and their activity can be aggregated to create metrics that can provide invaluable insights into the market.
Typical exchange metrics include:
- The balance held by exchange addresses [Live Chart]
- The volume of coins flowing into and out of those addresses [Live Chart]
- The number of deposits/withdrawals to/from those addresses [Live Chart]
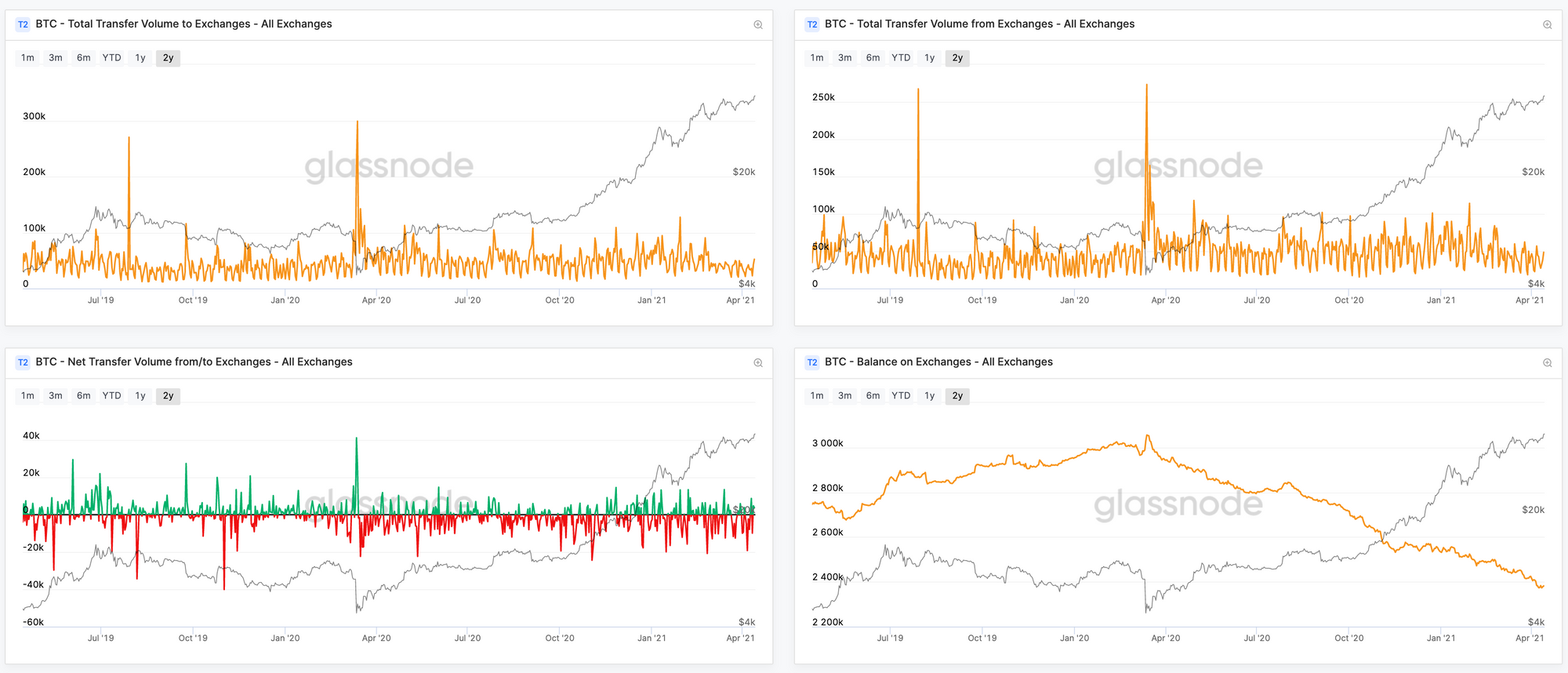
Why are Exchange Metrics Important?
Some examples of exchange behaviours that may be of interest:
- Exchange reserves can tell us much about the supply side of the market. The depletion of the exchange inventory (as we have been experiencing) is indicative of investor sentiment and provides us with a valuable data point to understand current investor behaviour.
- Funds moving off exchanges can mean that investors are pulling their coins into self-custody and long-term cold storage. This points to a rather bullish picture given that storing BTC in self-custody wallets can be seen as an indication to hold long-term and therefore investors’ conviction of Bitcoin’s future value. Other potential explanations include increased activity of OTC desks and custody services as a result of institutional buying, or the usage of funds in other financial services (e.g. as collateral for lending/borrowing).
- Inflows into exchanges can be indicative of increased trading activity, investors looking to take profits, and/or to rebalance to derisk their investment portfolios.
How does Glassnode Track Exchange Addresses?
To track exchange addresses, we employ a variety of mechanisms that can be broadly divided up into three categories: verified addresses, external sources, and clustering.
Verified Addresses
This is the easy/obvious step. These are addresses that are officially verified to be controlled by an exchange. For instance, when an exchange has officially communicated (publicly or privately) that the address is indeed owned by them. These also include addresses that are verified by directly interacting with the exchange (e.g. by depositing funds).
External sources
Being an open ledger and having millions of users interact with exchanges, labels for exchange addresses can be found scattered across the web. This is the crowdsourced part of exchange labels. Some of those addresses can be confirmed in a straightforward manner. For many others this is not true – especially when different sources report conflicting information, e.g. source A associates an address with exchange X, while source B associates it with exchange Y.
At Glassnode, we make use of publicly available address labels but put them through a rigorous QA process that finally determines whether an address is indeed part of a particular exchange. Our QA process includes (amongst others) steps such as analysing the address activity, its type, their interaction with other network entities, their balance structure, and the number of external sources confirming their label. Our processes are streamlined and contain automated as well as manual steps.
Only if an address label can be confirmed with a very high probability and without conflicting information, it is verified by us and added to the pool of addresses that belong to an exchange.
Clustering
Heuristics and clustering algorithms are powerful tools to automatically infer addresses that belong to an exchange. With heuristics and clustering, a vast amount of addresses can be identified using only a handful of initially verified address labels. This is possible by employing powerful data science methods for statistical inference based on patterns and characteristics that are intrinsic to Bitcoin’s UTXO-based design. In fact, we are often able to identify hundreds of thousands of addresses given only a dozen initial addresses. This step is an essential one to properly track exchange labels and create metrics that paint a complete picture. Without these measures, meaningful exchange metrics are virtually impossible. With more data and improved methodologies, this approach becomes more accurate over time.
Glassnode's philosophy in this step is the same as with labels that are obtained from external sources: we optimize to reduce false positives. If the probability of an address label is not highly significant, we will not label the address. We rather miss an address, than label it with low certainty.
All in all the combination of these methodologies provide a powerful framework that allows us to obtain a full picture of on-chain exchange activity and provide transparency on these market pillars with highly informative metrics.
The Bad
The above sounds simple enough: Identify exchange addresses, and monitor how many coins those addresses are currently holding, i.e. how much funds are flowing into and out of those addresses.
Well, in theory, yes – but as usual, things are somewhat more complicated. Let’s take a closer look at some of the challenges that come with address labelling.
Exchange Addresses are not Static
Initially identifying exchange addresses and tracking those will not get you far. The set of addresses that belong to a certain exchange constantly changes – a lot.
For instance, Figure 2 shows the number of network addresses associated with a specific exchange. It illustrates the continuous growth of the exchange cluster, currently at almost 25 million addresses. Note that the bulk of those addresses are empty, while the number of addresses with a non-zero balance has remained at a level below 100,000. This is just one example of the highly dynamic nature of ever-changing exchanges wallets.
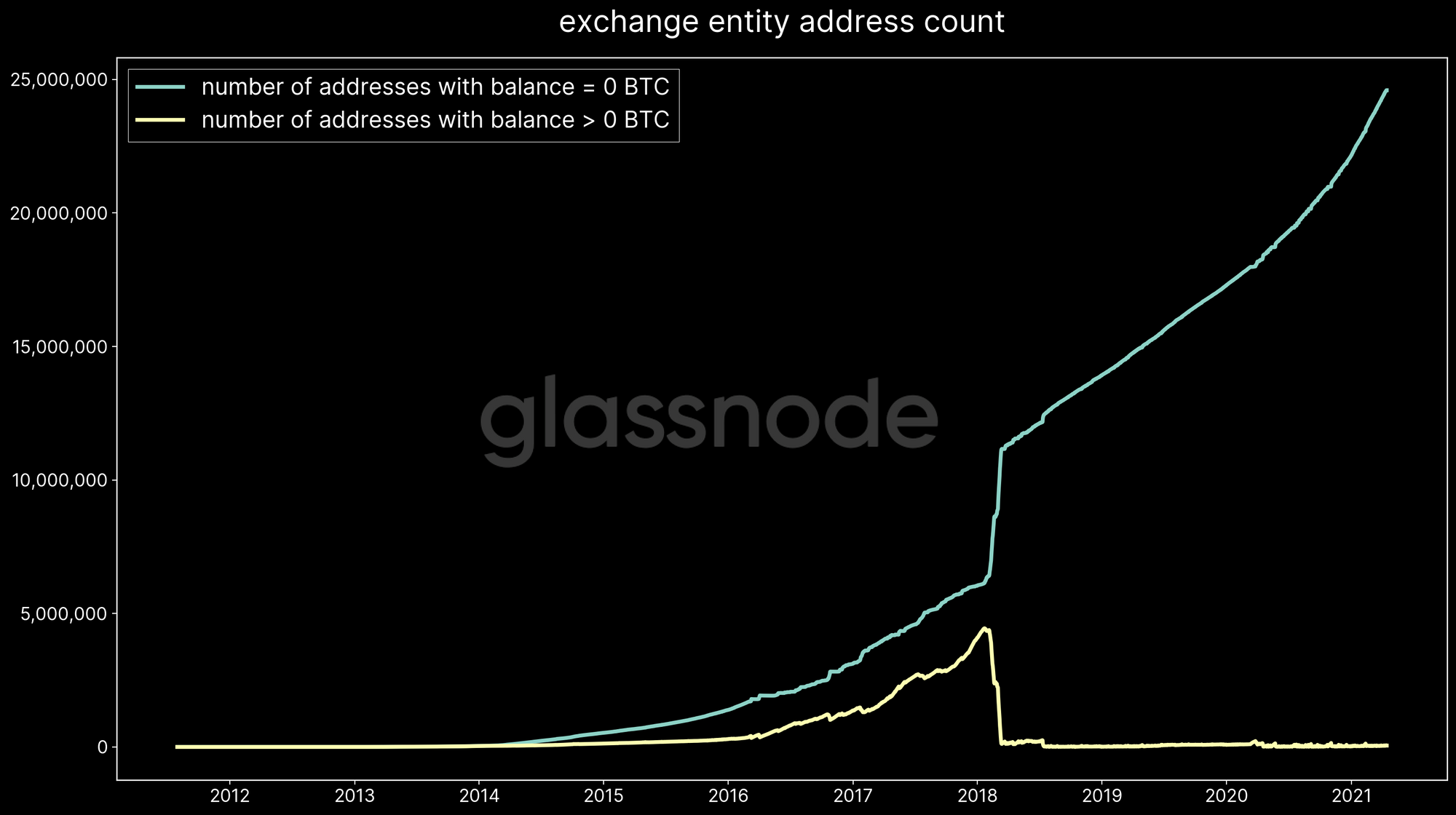
Hence, the biggest challenge is to have a reliable system in place that is capable of tracking those changes and keeps the current set of exchange addresses up to date.
Exchanges can (and do) continuously create new wallet addresses. This can be the creation of new cold wallets to which large amounts of coins are being transferred. Re-shuffling of funds into new wallets is commonly performed by exchanges. In addition, many exchanges employ mechanisms such as the non-reusability of addresses, therefore continuously creating new ones (e.g. to receive BTC change or relay funds to another address).
Furthermore, exchanges conform to high security and privacy standards and often employ mechanisms that include complex on-chain movements of funds with patterns that are unique to a particular exchange. These internal mechanisms differ a lot across exchanges and need to be identified and tracked for each exchange separately.
Finally, on-chain behaviour simply becomes more complex over time. Note that exchanges are multi-billion companies that provide financial services going beyond simple spot trading. Many offer futures trading or have spun up infrastructure for institutional custody. While the network layer is in theory agnostic to that development, it is reflected in the amount and complexity of on-chain movements. For instance, from a network perspective, it might not always be possible to immediately identify whether all custody wallets are included in the set of labelled exchange addresses. This depends on how those addresses are being used on a network level by the exchanges, which needs to be properly researched before final conclusions are made.
Given the above, it becomes clear that properly tracking exchange addresses is a non-trivial endeavour. We strive to employ the best mechanisms in the industry in order to obtain numbers that are as close to the truth as possible. But given the nature of exchange addresses, it must be clear that:
On-chain exchange data can be imperfect at times – at least on a single-transaction level. Some amount of uncertainty remains, as misses, or false alarms with respect to a particular in or outflow to/from an exchange are possible. Even though we have advanced methodologies in place, at times it can be impossible to immediately detect the sudden creation of a new cold wallet (an address that is seen in the network for the first time) that receives internal funds from another known exchange address. Many heuristics are only triggered once certain activity and patterns emerge over time. Note that this holds especially for sudden large transactions – the average transaction size moved inhouse by exchanges is often significantly higher than in and outflows (Figure 3).
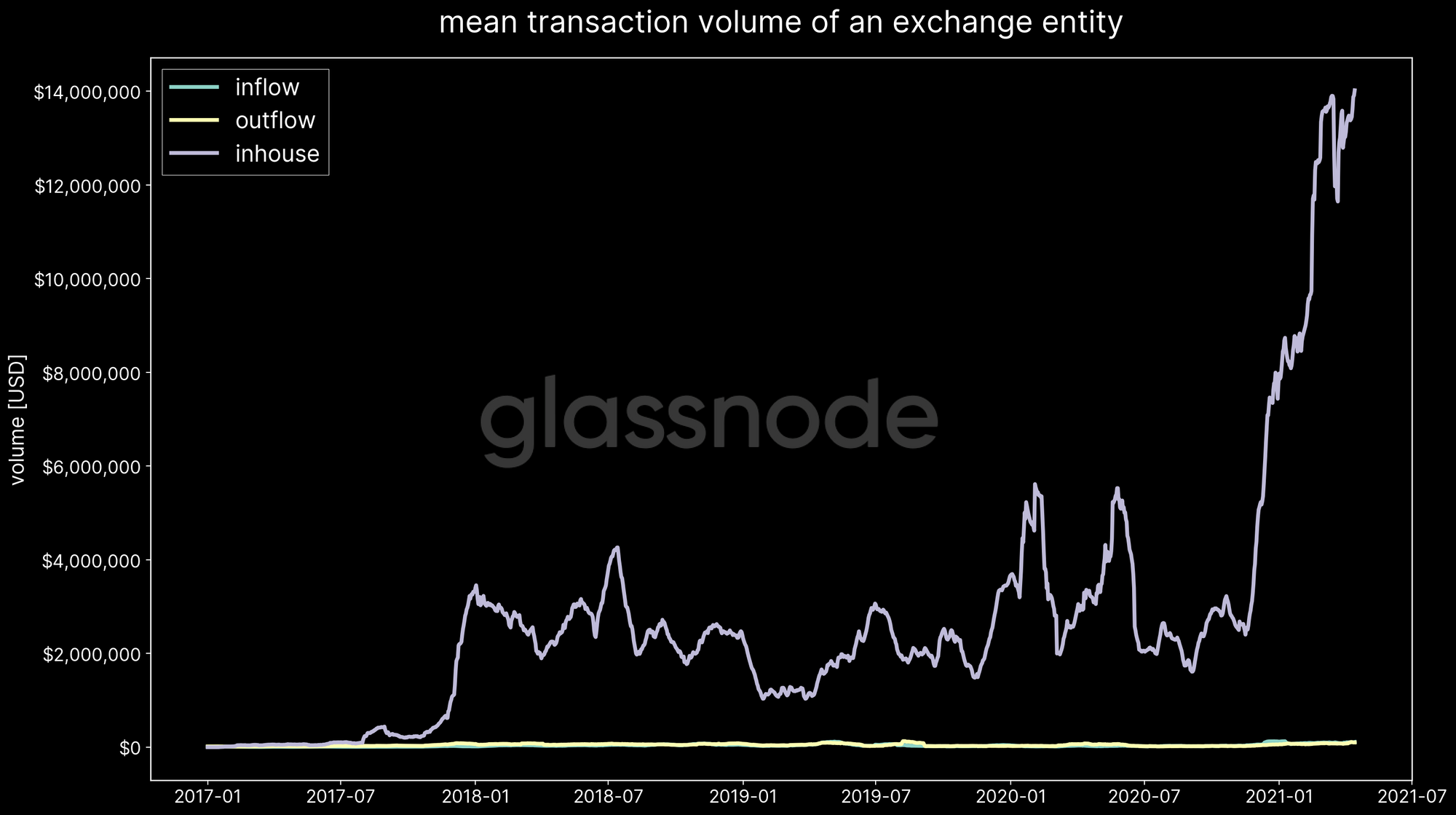
Please note that those inaccuracies only occur occasionally – exchange metrics are by large correct, especially when analysing mid and long-term trends.
The Ugly
What are the implications of the above? Simply put: exchange metrics are subject to change. New information can become available that adds (or in rare cases removes) an exchange address label. This can be due to information becoming available through either one of the channels mentioned above, e.g. an address that is officially verified by the exchange itself, or/and a heuristic or clustering that gets triggered and adjoins an initially unconfirmed address to an existing exchange cluster.
Ultimately this means that exchange metrics can historically change. Always keep that in mind.
Conclusion
Does this mean that exchange metrics are useless? Not at all, on the contrary!
Even if every single exchange flow can’t always be immediately verified, it is most essential to understand exchange activity. Exchange metrics are complete for the most part and have proven to give invaluable insights to researchers, investors, and traders over the years.
Transparency on exchange activity is highly important, especially given the number of reports of fake volumes and wash trading we have seen in the past. Analysing on-chain exchange activity gives access to a completely new, verifiable and incorruptible data source, and should be part of any investors’ toolset.
In our opinion, it is simply important that users understand how these metrics are computed to help investors to make better sense of them.
Main Take-Aways
- On-chain exchange data is challenging and single in/outflows can at times be initially unconfirmed. This is simply because that exchanges employ complex on-chain processes that constantly change their network addresses.
- On-chain exchange metrics can historically change. This is due to a) clustering algorithms that automatically update the set of exchange addresses with increasing statistical information and b) by manually adding new verified exchange labels. While the former happens daily, it only slightly influences the most recent data. The addition of new labels can have a bigger impact on historic data, but only happens very infrequently and is always announced in our changelog.
- We optimize to reduce false positives. This means that the probability of removing an address label is much much lower than adding one. If a label is part of an exchange, it most certainly will forever be.
- Be careful and mindful of short-term exchange information. This holds especially concerning large (single transaction) outflows from an exchange. Those should always be investigated. A sudden outflow of 10k BTC from an exchange can turn out to be simply an internal transfer. While our algorithms pick up immediately on many of those, some are simply not detectable right away and only manually verifiable within hours until they are reflected in our data.
- The above points are especially important to keep in mind if you are using exchange metrics to (day-)trade. First, initial single-transaction out/inflows can be retracted if they are eventually identified as an internal transaction. Second, as historic data changes, this can influence your models and backtesting. Always keep this in mind if you train models based on exchange metrics.
We hope that with the above information we were able to increase transparency concerning the challenges and caveats that come with exchange metrics.
Exchange data is extremely helpful for any trader, researcher, investors, and hodler.
We will continue to strive to bring you the best exchange data in the industry.
Many thanks to Checkmate for reviewing this work.

- Follow us and reach out on Twitter
- Join our Telegram channel
- For on–chain metrics and activity graphs, visit Glassnode Studio