Presentamos los Datos Impuntuales: Abordamos la Mutabilidad de las Métricas del Blockchain
Hablamos de cuándo y cómo de rápido se actualizan las métricas del blockchain que ofrece Glassnode y analizamos el impacto y magnitud de las actualizaciones de los datos que las componen. Además, presentamos métricas con datos impuntuales que no sufren ajustes de anticipación imparciales.

En Glassnode ponemos a tu alcance el conjunto de métricas del blockchain más comprensibles que existen, disponibles para una serie de crypto activos. Como su propio nombre indica, la información que las compone se extrae directamente del comportamiento y actividad que emana directamente de las entrañas del blockchain. Transformar el bruto de esa información en métricas no es siempre un proceso claro y sencillo, está más bien plagado de retos y matices, algunos de esos aspectos son muy relevantes para los usuarios que emplean esas métricas. En este artículo, tratamos de arrojar algo de luz sobre el funcionamiento del proceso básico que utilizamos para computar nuestras métricas y sobre la naturaleza en sí de los datos que en general produce el blockchain.
Queremos en particular centrarnos en dar respuesta a las siguientes cuestiones:
- Disponibilidad de la información: ¿Cómo exactamente se propaga a nuestras métricas la información que contiene el blockchain y cuánto tarda en hacerlo? ¿Cuándo se puede considerar que un dato concreto está realmente “completo”?
- Mutabilidad de la información: ¿Hasta qué punto pueden las métricas del blockchain cambiar a medida que pasa el tiempo? ¿Qué razones hay para que se produzcan esos cambios, a qué temporalidades puede afectar y qué orden de magnitud se espera que alcancen las posibles actualizaciones de estos datos?
Como ya iremos viendo, la posibilidad de que algunos datos cambien hace que algunas métricas presenten problemas para según qué usos, por ejemplo el backtesting. Es por esto que presentamos un nuevo grupo de métricas hechas a medida para este fin específico, donde la inmutabilidad de los registros históricos se convierte en algo extremadamente importante: las métricas de datos impuntuales.
Disponibilidad de la Información
Tanto desde la perspectiva de la recolección de datos como en sentido literal, la cadena de bloques se compone simplemente de “bloques”. A continuación vemos el camino que recorre un bloque a lo largo de varias etapas: desde su creación y distribución por el la red global hasta nuestra propia infraestructura y finalmente nuestras métricas. Para entender cuándo la nueva información disponible se ve reflejada en nuestras métricas, es crucial entender antes cómo funcionan estos pasos individuales y cómo puede cada uno de ellos afectar el tiempo que le lleva a una métrica actualizarse totalmente.
El viaje de un bloque hacia nuestras métricas
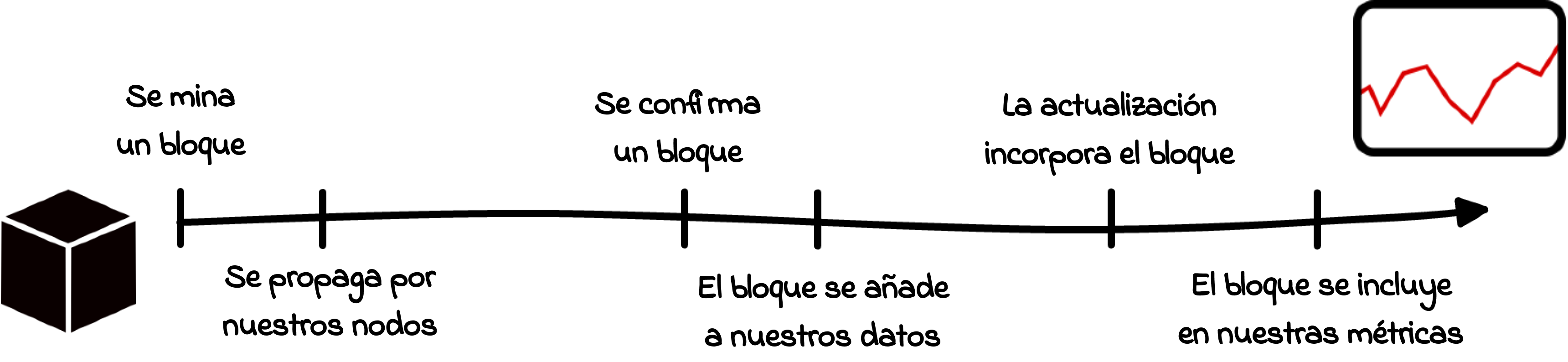
Paso 1: Se mina un bloque
Los nuevos bloques se adhieren a la cadena de uno en uno, haciendo siempre referencia los bloques que le preceden. En el caso de Bitcoin esto se consigue tomando prestada la estructura de la Prueba de Trabajo (PoW). En términos llanos esto significa: Una vez que los mineros resuelven el problema criptográfico, los bloques que generan se convierten en una extensión legítima de la cadena y ya pueden distribuirse a través de todos los nodos de la red. Estos últimos a su vez validan los bloques y eventualmente se alcanza el nivel de consenso al acordar que la cadena más larga representa la nueva imagen del blockchain. En contraste, Ethereum recientemente ha pasado a adoptar el sistema por Prueba de Participación (PoS). Este mecanismo de consenso delega el papel de los mineros en los validadores, quienes deben depositar un capital de 32 ETH para poder participar. Sin entrar en demasiados detalles, hay que decir que un algoritmo asigna a los validadores que producen los bloques y el resto certifica dichos bloques.
Registro temporal del bloque
Demos un paso atrás por un momento: Aparte de las soluciones criptográficas (PoW) o el consenso informativo (PoS), un bloque porta una cierta cantidad de transacciones (que p.ej. en el caso de Ethereum pueden incluir complejos contratos inteligentes) y, entre otros tipos de información, un registro temporal fijo asociado al momento de creación de ese mismo bloque. Es precisamente este registro temporal el que más tarde decidirá a qué periodo de tiempo de la métrica contribuirá el bloque.
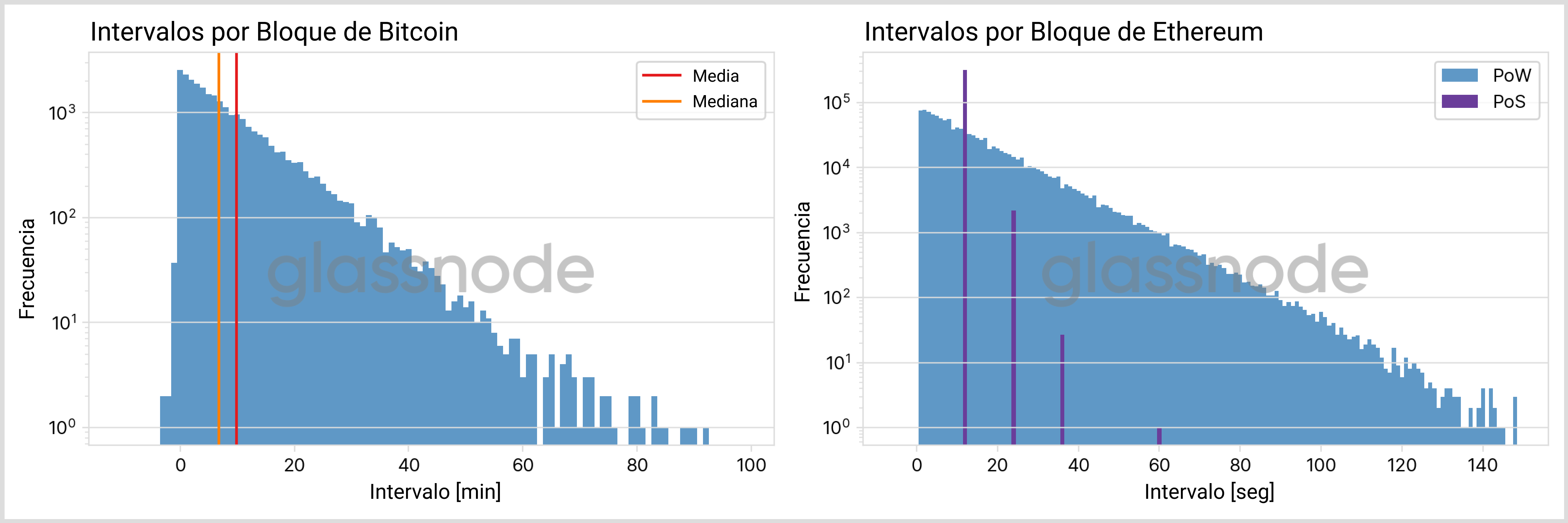
En los blockchain PoW el intervalo entre dos bloques adjuntos es probabilístico, la duración media sólo se controla indirectamente a través de la Dificultad. En la Fig. 2 mostramos la distribución de estos intervalos en BTC y ETH (“pre-Fusión”), con el intervalo en el eje de las x y la frecuencia en el eje de las y. En la era “post-Fusión” de ETH con su mecanismo PoS, se crean bloques en espacios con intervalos fijos, en forma de distribución discreta.
| BTC | ETH (POW) | ETH (POS) | |
|---|---|---|---|
| media | 9:50 min | 13 s | 12 s |
| mediana | 6:47 min | 10 s | 12 s |
| percentil 90 | 22:38 min | 31 s | 12 s |
| percentil 99 | 44:44 min | 1:01 min | 12 s |
| max | 1:45 h | 2:52 min | 1:00 min |
De estas gráficas podemos concluir lo siguiente:
- Si bien es cierto que el intervalo por bloque en su mayoría es pequeño, hay veces en las que el tiempo entre bloques puede superar con creces el intervalo medio. En el caso de BTC se han registrado cifras por encima de 1 hora (mientras que el intervalo medio apenas es de alrededor de 10 minutos), con ETH (PoW) en el peor de los casos se puedía llegar a tardar algo más de 2 minutos para adherir un nuevo bloque a la cadena (ver la tabla anterior para más detalles).
- La curvatura continua es señal de una Distribución Exponencial. Desarrollaremos este aspecto en más profundidad a continuación.
- El intervalo por bloque de ETH (PoS) se concentra siempre en los 12 segundos, que es el tiempo de intervalo entre espacios que dicta el mecanismo de consenso. Cuando se supera una o varias veces esta unidad de tiempo fundamental se debe a los “bloques perdidos”, es decir, situaciones en las que un validador no propuso el nuevo bloque a su debido tiempo.
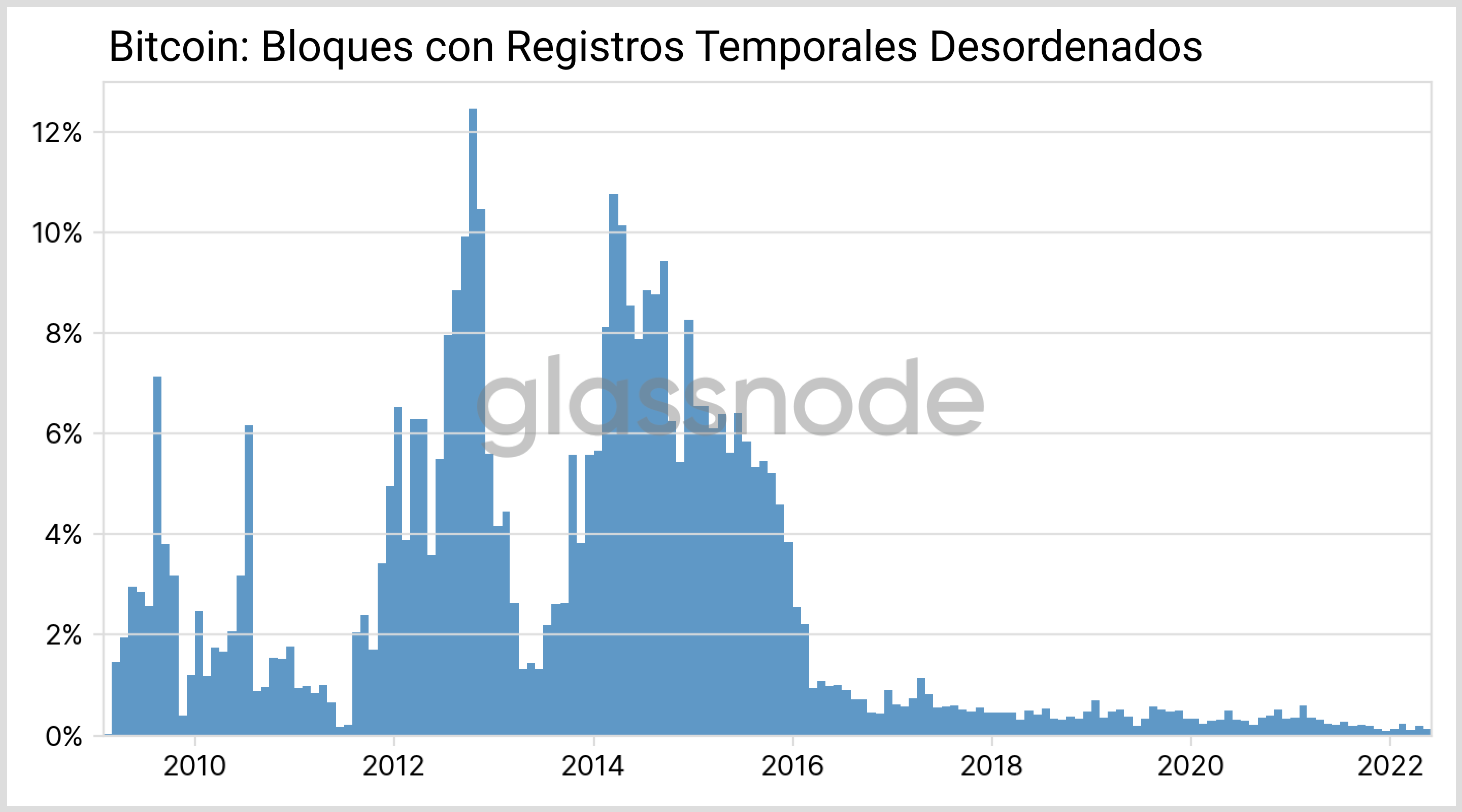
Sorprendentemente, también encontramos un tiempo negativo en algunos intervalos de BTC: Normalmente podemos asumir que se han sincronizado bloques empleados por diferentes mineros, lo que es posible gracias a estándares como el Protocolo de Tiempo del Network. Significa que los registros temporales de cada bloque consecutivo van siempre en aumento y ordenados. De hecho, este es un requisito muy estricto descrito en el Yellow Paper de Ethereum. En Bitcoin, sin embargo, las condiciones son algo más flexibles y no se imponen secuencias temporales monótonas. Aunque en estos últimos años cada vez escasean más los registros temporales fuera de orden (ver Fig. 3).
Paso 2: Difusión
Tras crearse (“minarse”) un nuevo bloque de BTC, es difundido a través de la red global de nodos. Esto ocurre a una velocidad mucho más rápida de lo que duran de media los intervalos por bloque. Por ejemplo, en el caso de BTC tan solo pasan un par de segundos hasta que casi toda la red al completo recibe el nuevo bloque, mientras que el intervalo entre dos bloques ronda los 10 minutos de media. Este lapso de propagación es el que suele tardar para nodos generales, pero la transferencia de datos entre mineros puede ser aún más rápida gracias a técnicas como la FIBRE. Podríamos perfectamente asumir que los diferentes pools de minería se esfuerzan por reducir la latencia todo lo posible, para evitar las bifurcaciones del blockchain y conseguir que la minería rinda más eficientemente y con menos costes.
De igual modo, la distribución de los bloques nuevos de ETH (PoS) depende de sus validadores y por tanto también ocurre a gran velocidad.
Paso 3: Confirmación del bloque
Ahora veamos qué ocurre con el bloque dentro de la infraestructura de Glassnode: Cuando un nuevo bloque alcanza nuestros propios nodos, esperamos a que se confirme el bloque antes de utilizar la información que contiene. El motivo principal por el que esperamos esas confirmaciones es evitar las modificaciones de los datos finales, p.ej. reduciendo la probabilidad de incluir desde un principio bloques que terminan siendo huérfanos. Para BTC y ETH, por ejemplo, esperamos 1 y 12 bloques adicionales respectivamente hasta que un bloque realmente se tiene en cuenta en nuestro conjunto de datos.
Nota aparte: El retardo total resultante de estas medidas de seguridad puede estimarse matemáticamente. Para ETH (PoS), donde el tiempo entre bloque y bloque es siempre de 12 segundos, lo que nos lleva menos de 2,5 minutos (12 x 12 segundos). Para Bitcoin, si asumimos que los relojes mineros están bien sincronizados y que el hash rate se mantiene más o menos constante, entonces podemos formular el minado de bloques como un proceso de Poisson. Es evidente por las distribuciones exponenciales que hemos observado en la Fig. 2. Por tanto el tiempo que pasa entre un cierto número de bloques atiende a una distribución Erlang, donde la cantidad de bloques confirmados determina la “forma” y el intervalo por bloque medio el parámetro de “ritmo”. Al compensar el retardo de propagación y el tiempo que tardamos en transcribir la información en nuestro conjunto de datos, obtenemos un retraso total que se acerca mucho al retardo real tal y como lo hemos desarrollado.
Paso 4: Actualización de métricas
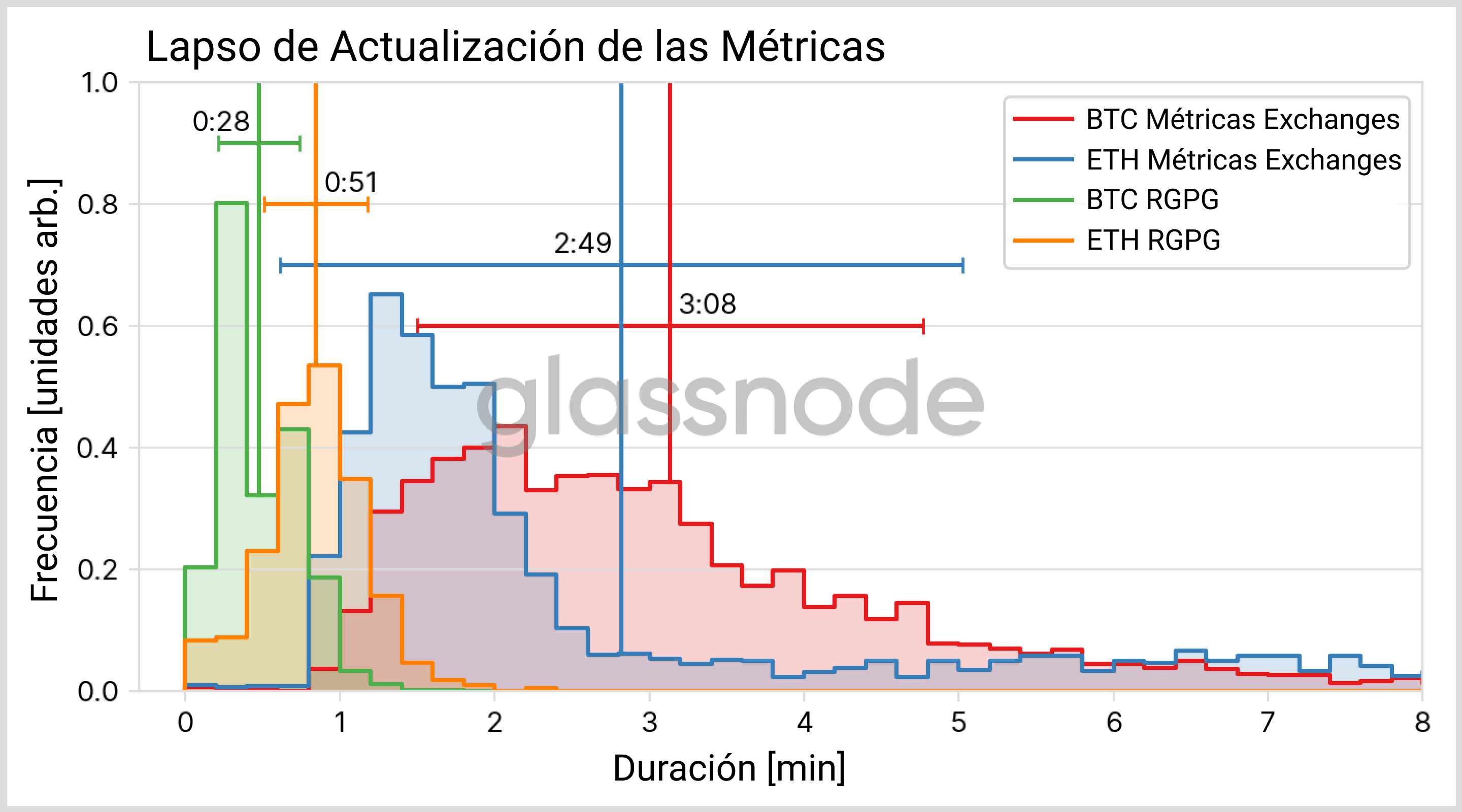
Llegamos al último paso en el viaje que recorre el bloque para ser incluido en una métrica: Uno de nuestros programas analiza el grupo de datos actualizados, realiza ciertas computaciones y añade la nueva información a nuestra métrica. Actualmente las actualizaciones están programadas para que tengan lugar a intervalos que dependen de la resolución de la métrica en cuestión. Por ejemplo, las actualizaciones de las métricas con resolución de 1 día se actualizan a las 00:00:00 UTC, y cada diez minutos completos se actualizan las métricas con una resolución de 10 minutos (para más detalles ver nuestra documentación aquí). De modo que, incluso para estos últimos, tenemos que esperar entre cero y diez minutos extra, de media acaban siendo cinco minutos, hasta que se tiene en cuenta la información que porta el bloque. El lapso de tiempo real que discurre hasta que se actualiza del todo depende enormemente de la complejidad de la métrica en sí y puede variar de segundos a unos minutos, la Fig. 4 contiene algunos ejemplos.
Ruta de viaje
Vamos a resumir las diferentes partes que suman tiempo total hasta que se actualizan nuestras métricas:
- Desde que un bloque se crea con éxito, se propaga a través de los diferentes nodos de la red, y es un proceso que tarda unos segundos en completarse.
- Antes de agregar el bloque a nuestro registro de datos, esperamos a que se confirme dejando pasar una cierta cantidad de bloques que depende de cada activo. En base a la cadena en cuestión y su intervalo por bloque medio, el tiempo requerido ronda entre 1-10 minutos. En algunos casos extremos la confirmación puede demorarse hasta una hora o más.
- Transcribir la información en nuestro conjunto de datos lleva normalmente menos de un minuto.
- La computación de la métrica comienza con un retardo de entre cero y diez minutos (para aquellas métricas con resolución de 10 minutos).
- Los programas de actualización tardan entre unos segundos y varios minutos en reproducir los nuevos datos y ponerlos a disposición a través de nuestra API.
Como cada una de las partes que acabamos de enumerar es independiente, el retardo total puede estimarse con la circunvolución de sus distribuciones individuales.
Cifras, por favor
Para determinar si el razonamiento descrito anteriormente está completo, vamos a ver algunos ejemplos reales. Para ello, hemos escogido las Direcciones Depositantes en los Exchanges como métrica representativa de tanto BTC como ETH, hemos examinado nuestros archivos de registro y extraído todas los registros temporales necesarios.
El resultado del análisis está representado en la Fig. 5 de abajo. La distribución teóricamente esperada se ha determinado usando un único parámetro libre, ubicado a lo largo del eje temporal, y tiene en cuenta el tiempo de propagación desde los mineros hasta nuestros nodos y la combinación de procesos rutinarios que lleva a cabo nuestro software. Hay que recalcar que la forma de nuestra distribución no se ve afectada por el parámetro libre y en su lugar depende exclusivamente del modelo que hemos descrito anteriormente.
No es de sorprender que debido a su menor intervalo por bloque y sus inferiores periodos de confirmación, los nuevos datos llegan a las métricas de ETH mucho más rápido que a las de BTC. Mientras que se puede esperar que el bloque de ETH se incorpore a nuestras métricas a los 15 minutos más o menos, la distribución más prolongada de BTC registra una duración de entre 30 minutos y 1 hora, donde la cantidad exacta depende del marco probabilístico que se escoja.
La siguiente tabla resume las cantidades más relevantes de las distribuciones resultantes (métricas con una resolución de 10 minutos).
| BTC | ETH (POW) | ETH (POS) | |
|---|---|---|---|
| media | 20 min | 10 min | 9 min |
| percentil 25 | 13 min | 7 min | 7 min |
| mediana | 18 min | 10 min | 9 min |
| percentil 75 | 25 min | 12 min | 12 min |
| percentil 90 | 34 min | 14 min | 13 min |
| percentil 99 | 57 min | 16 min | 15 min |
¿Cuándo está un dato concreto realmente completo?
Hasta ahora hemos hablado acerca de bloques individuales y cuándo estos se abren paso hasta verse reflejados en nuestras métricas. No obstante, podemos hacer preguntas complementarias: ¿Cuánto tiempo pasa hasta que se recolectan todos los bloques comprendidos en un intervalo? O dicho de otra manera: ¿Cuándo se procesan todos los bloques cuya información contribuye a dar por completo el dato común de una métrica?
El término “completo” que empleamos aquí no implica necesariamente que ese dato concreto sea inmutable: Su valor no volverá a cambiar por haberse completado posteriormente otros bloques nuevos, pero puede haber otras maneras de actualizar esa información. Discutiremos esas causas en la sección de “Mutabilidad de la información”
Actualizaciones repetidas
Por todo lo anterior es obvio que en general no todos los bloques son inmediatamente incluidos nada más estar su información disponible, y se debe a los retrasos intrínsecos que cada bloque individual puede encontrar en su camino hacia las métricas.
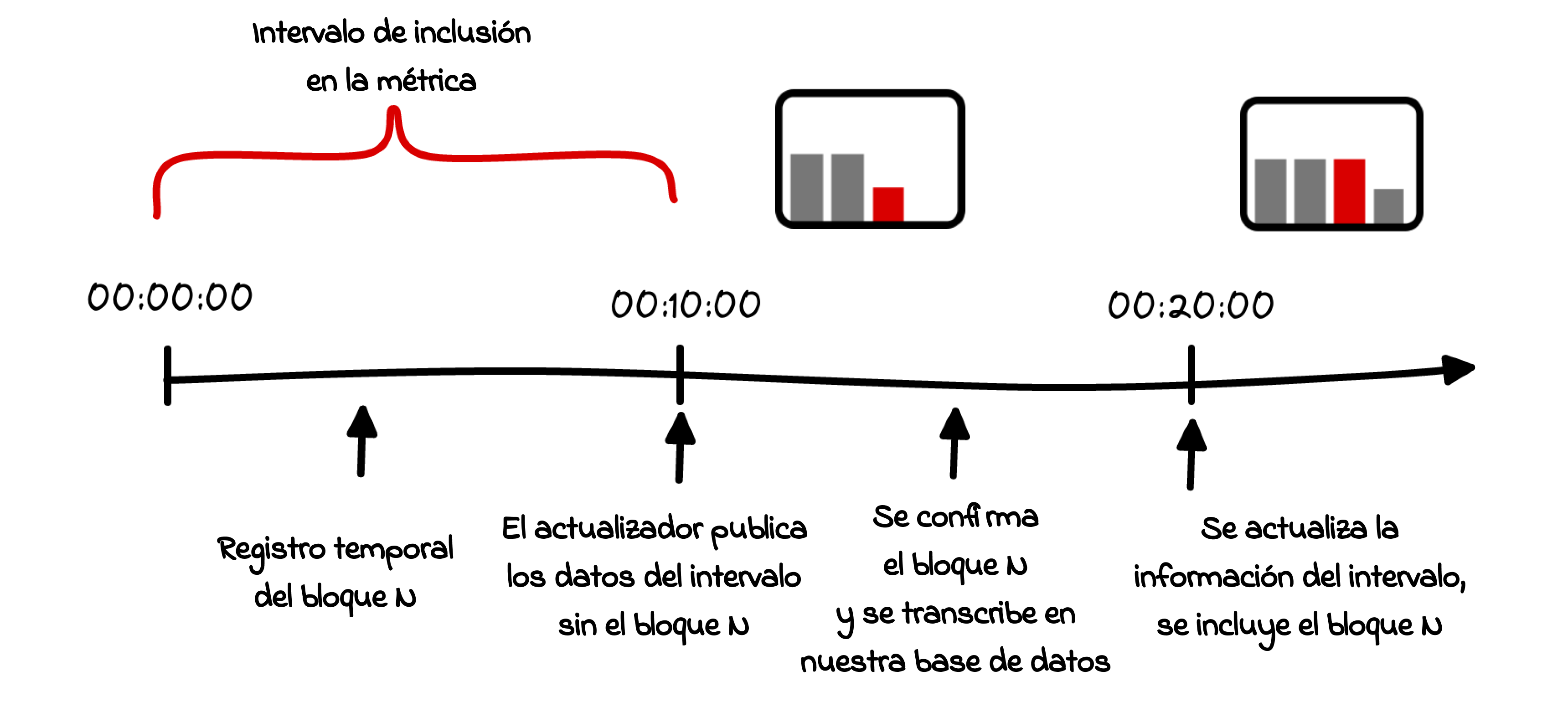
Por ejemplo, consideremos el caso que se muestra en la Fig. 6. Vamos además a suponer un registro temporal exagerado de 00:09:59 para el bloque N, el cual eventualmente contribuirá al dato impreso a las 00:00:00 (Es importante saber que la temporalidad de nuestras métricas siempre hace referencia al inicio del intervalo en cuestión). En las métricas con resoluciones de 10 minutos, el proceso de actualización que empieza a computar la información se activa a las 00:10:00, es decir, apenas al segundo siguiente de la creación del bloque. Lógicamente, este intervalo es demasiado corto para permitir que se propague por los nodos del blockchain, se lleven a cabo las confirmaciones pertinentes, se procesen los datos, etc. Por eso lo más probable es que la información de dicho bloque sólo se vea reflejada a las00:20:00, es decir, se introducen los datos en retrospectiva, y sólo entonces se modifica el valor existente. Estas causas de por qué madura la información son particularmente relevantes en blockchains con una frecuencia de bloques elevada.
Puede presentarse una situación similar por los registros temporales desordenados de BTC (ver Fig. 3), tal y como se ha dado a entender anteriormente: Un nuevo bloque añadido a la cadena que tenga un registro temporal inferior al del bloque previo, puede llegar a hacer que cambie un dato impreso anteriormente. Afortunadamente, estos intervalos negativos entre bloques son muy limitados y apenas han aparecido en el último par de años, como se muestra en la Fig. 3.
Publicaciones retrasadas
En Bitcoin pueden ocurrir algunos casos límite de naturaleza muy distinta. En lugar de tener múltiples bloques aportando la misma información a una métrica, nos podemos encontrar con que sencillamente no haya bloques que participen para aportar información en un intervalo. Es un problema que puede surgir en métricas con resoluciones de 10 minutos y (menos frecuentemente) con las de 1 hora, porque el intervalo del bloque tenga la misma envergadura. Por su parte, el blockchain de Ethereum siempre contiene al menos un par de bloques en cada dato registrado, incluso en la resolución de 10 min, lo que puede verse en la distribución de los intervalos de la Fig. 2.
Tales franjas de datos inicialmente “vacías” se publicarán junto a la siguiente franja “no-vacía”, que incluya de nuevo bloques reales. Sus valores dependen del carácter de la métrica: P.ej. en el Recuento de Transacciones se considera que el valor es cero, mientras que en la Oferta en Circulación se duplica el último valor conocido.
Cuantificando cuánto de completo
Para abordar la cuestión de lo completa o no que esté la información que hemos mencionado al comienzo de esta sección, tenemos que considerar dos temporalidades con distintos puntos de partida.
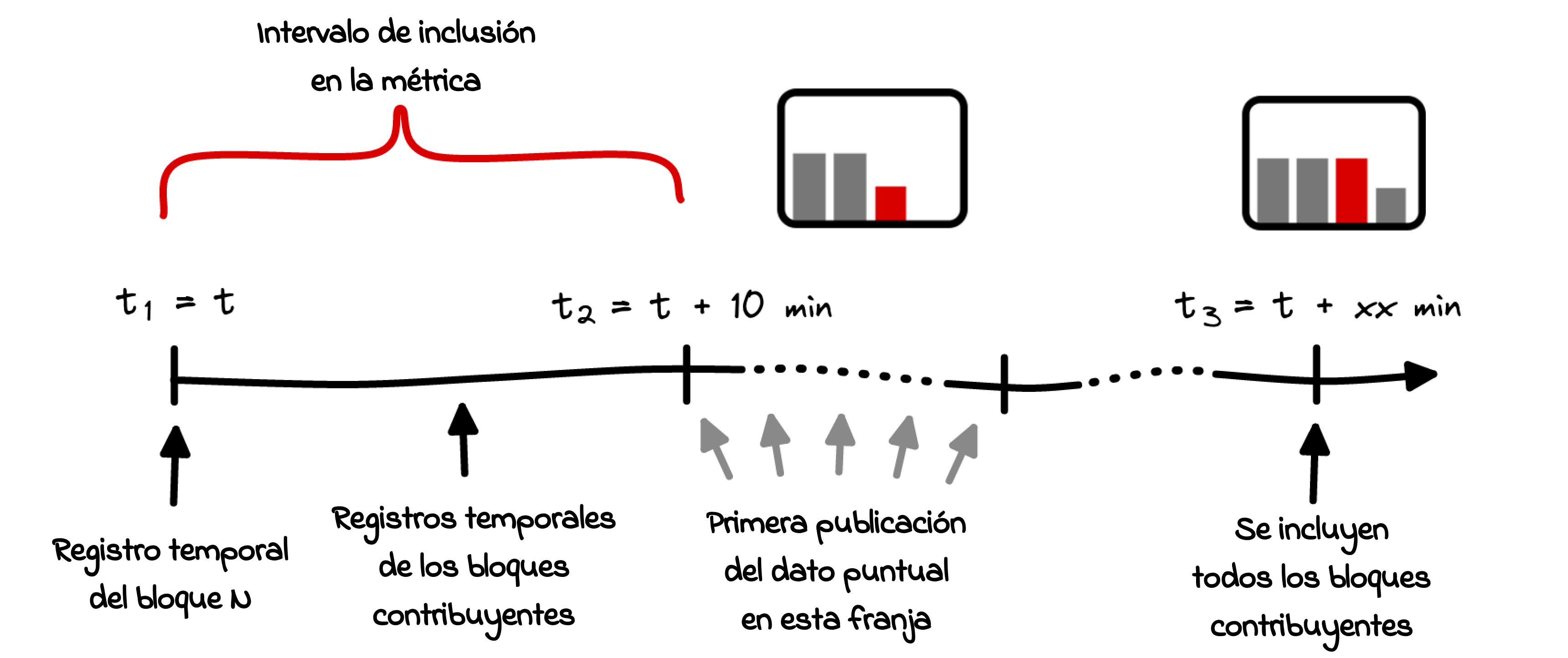
- Lapso entre el registro temporal de un dato y el tiempo que transcurre sin que contribuyan más bloques. El boceto que muestra la Fig. 7, corresponde del tiempo t₁ hasta el tiempo t₃.
- El lapso de tiempo entre la primera publicación de un dato y el tiempo que tarda en completarse, corresponde al intervalo t₂ – t₃ de la Fig. 7. Como la publicación del nuevo dato siempre respeta la temporalidad de la métrica el lapso finalmente es menor.
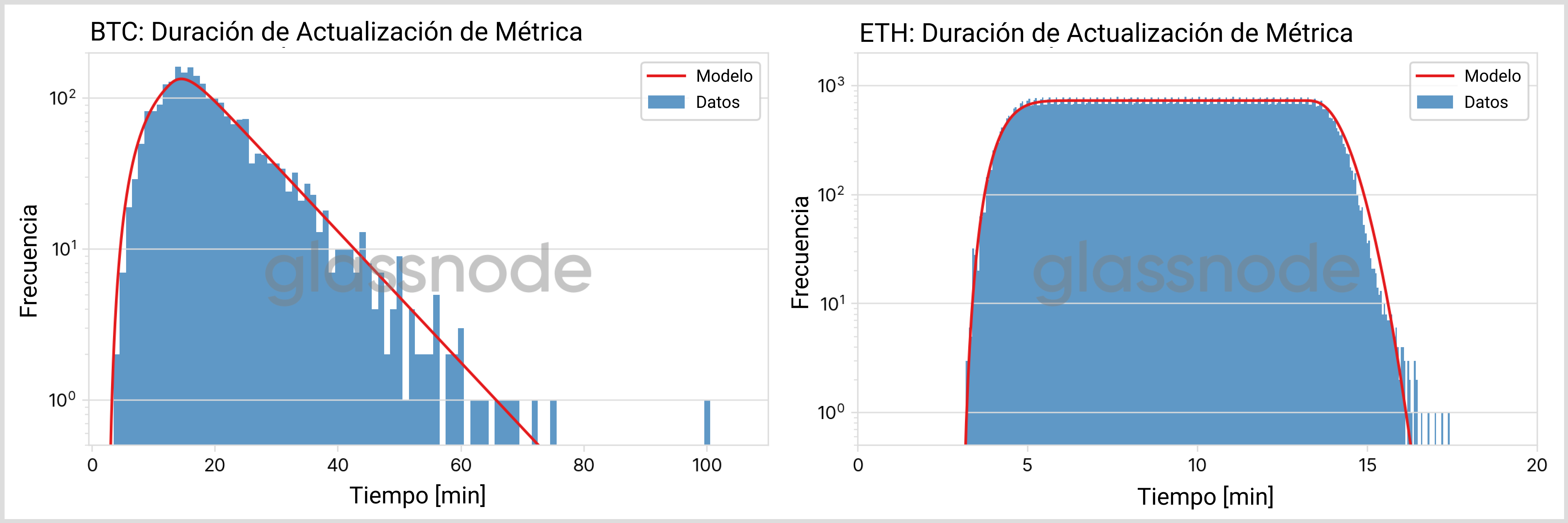
Para clarificar, nos vamos a enfocar de nuevo en métricas con una resolución de 10 minutos, e ignorar el tiempo que lleva procesar la actualización, para llegar al resultado independientemente de la métrica que escojamos. De nuestros registros podemos extraer las cantidades más comunes para las métricas de BTC, tal y como mostramos en la Fig. 8.
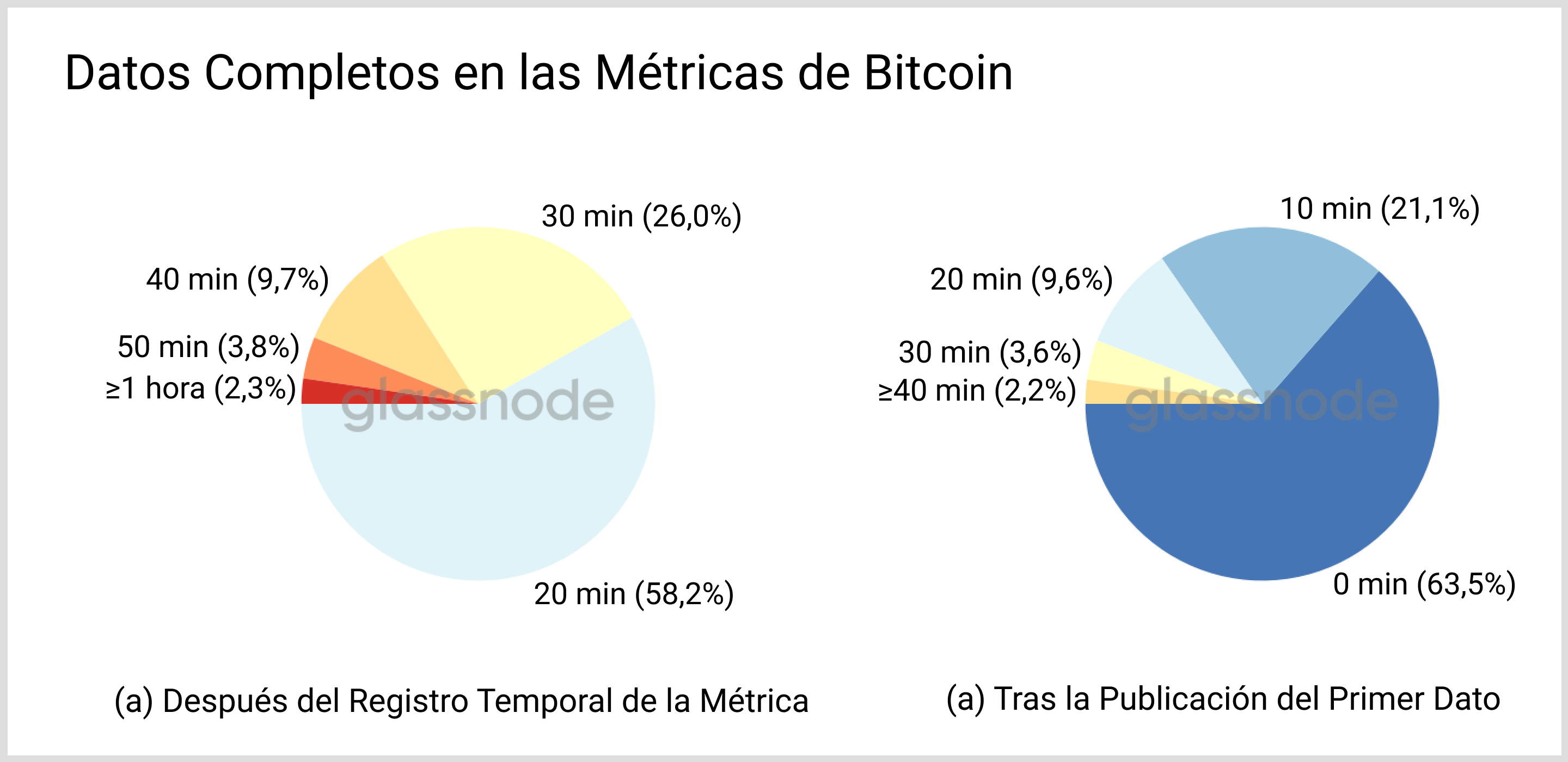
En la gráfica derecha en la Fig. 8, observamos que en torno a 2/3 de la nueva información generada terminan siendo definitivos y no cambiarán debido a la adición de los bloques consecutivos. En el resto de franjas de datos las actualizaciones repetidas cada vez son más y más infrecuentes. Cuando tomamos como referencia el registro temporal de una métrica (panel izquierdo de la Fig. 8), cerca del 85% de los datos puntuales se completan en menos de media hora.
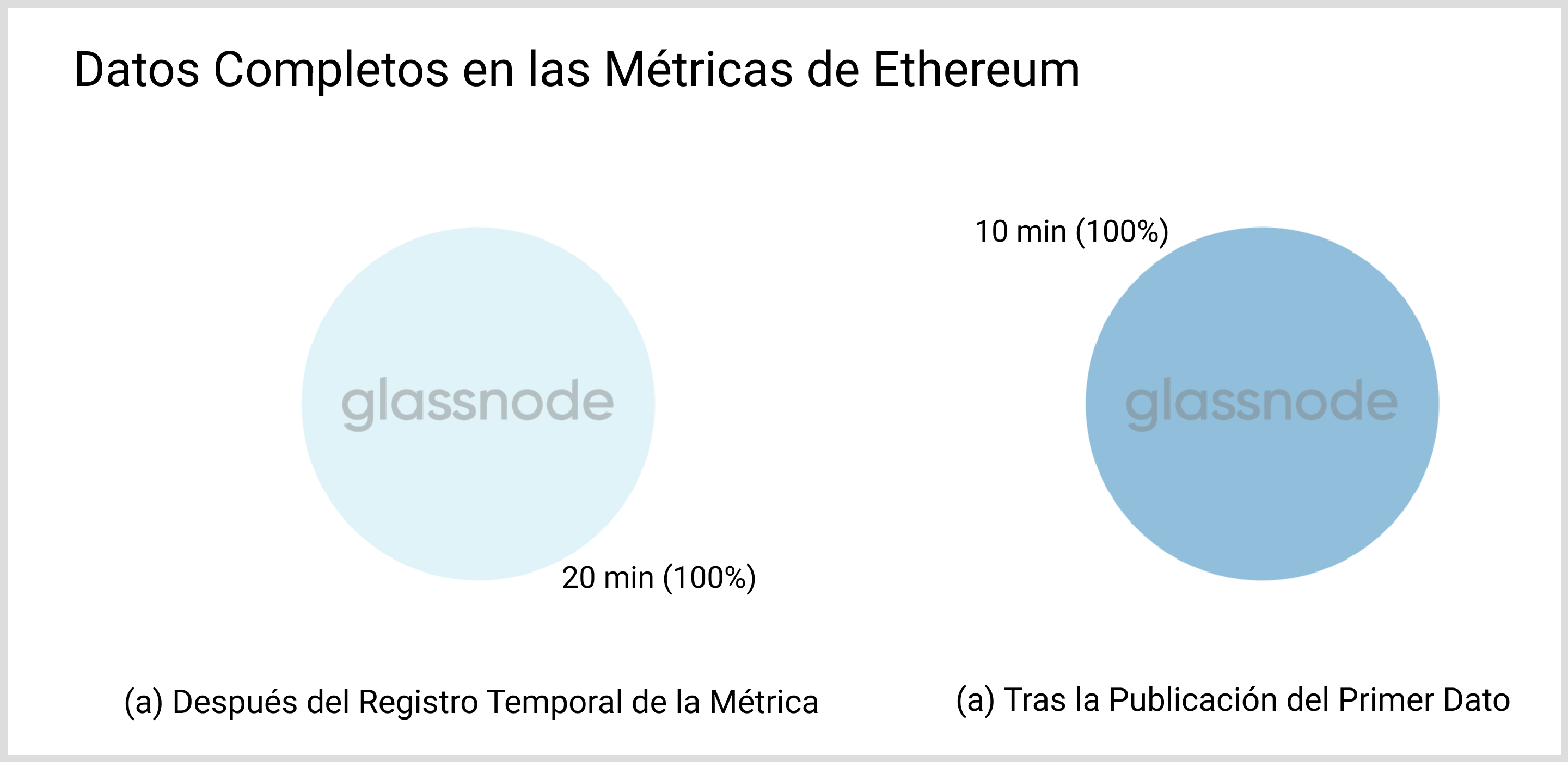
Para ETH (tanto PoW como PoS), los resultados son menos espectaculares, ver Fig. 9. El intervalo medio por bloque (~12 seg) es muy inferior a la resolución de las métricas escogidas (10 min) y por tanto la primera mutación de datos posible que ilustramos en la sección “Actualizaciones repetidas” afecta a toda la información presente en un conjunto de datos. Por este motivo, no existen coletillas en su distribución temporal.
Mutabilidad de la información:
En lo que respecta a los cambios de información, hasta ahora hemos considerado siempre causas intrínsecas de nuestras propias métricas del blockchain. Por las razones que hemos expuesto, y de algún modo paradójicamente, hasta las métricas más elementales que se derivan de las propias entrañas del blockchain están sujetas a cambios, incluso a pesar de que el mismísimo blockchain sea inmutable. Como hemos podido ver, las razones no son otras que las inevitables demoras que se producen cuando procesamos nuevos bloques. Por suerte, las repercusiones de la variabilidad de la información sólo afectan a los registros temporal más recientes y, como decíamos antes, todos los valores se estabilizan en un corto periodo de tiempo.
Pero a pesar de esto puede que surjan otras causas que alteren los datos, y aparecerán dependiendo del tipo de métrica. Por ello es interesante desarrollar estos tipos en orden ascendente de complejidad.
Motivos de cambios en los datos
Métricas del blockchain estándar
Denominamos “métricas estándar” a aquellas que se derivan directamente de la información bruta contenida en el blockchain. Ninguna información adicional entra en estas computaciones, p.ej. datos que provengan de fuentes externas o que requieran análisis estadísticos avanzados. Algunos ejemplos engloban el Número de Bloques o la Oferta en manos de las Direcciones Ballena. Pueden ponerse en marcha los siguientes mecanismos que alteren esta información:
- Demoras intrínsecas: Como hemos discutido anteriormente en todo detalle, los últimos datos que refleja una métrica están sujetos a cambios por el inevitable retraso que sufre un bloque en su viaje hasta nuestras métricas.
- Reorganización de la cadena (“reorg”): La cadena más larga es la globalmente aceptada. Si por un momento dos cadenas tienen el mismo tamaño, puede ocurrir que un nodo siga temporalmente al blockchain “incorrecto”. En casos así puede ser necesario desechar unos cuantos bloques y sincronizarse de nuevo con la cadena principal. A su vez, han de actualizarse las métricas que hayan incluido información contenida en la rama descartada. Para minimizar este efecto es por lo que esperamos un cierto número de bloques confirmantes, para verificar el buen estado de las información que atraviesa nuestros nodos (ver la parte relacionada de la disponibilidad de las métricas de más arriba). Gracias a esta medida cautelar los reogs que se producen difícilmente provocan cambios alteraciones en las métricas.
Métricas que incluyen datos externos
Algunas de nuestras métricas requieren cierta información adicional proveniente de terceras partes y fuentes externas. El ejemplo más evidente es el precio actual e histórico de un activo. Ejemplos de estas métricas incluyen la Capitalización de Mercado o el Porcentaje de Direcciones en Ganancias. Además de estos cambios en los datos, podemos cruzarnos con el siguiente:
- Información atrasada, incorrecta o ausente por parte de los proveedores de datos externos: Tales instancias son raras de ver, pero pueden requerir recomputar las métricas afectadas desde que entró la información extra que hay que actualizar o reemplazar. Dichos cambios se anuncian siempre en nuestros Registros.
Métricas de agrupación
En el caso de Bitcoin tenemos continuamente funcionando de forma automatizada múltiples procesos heurísticos, que se encargan de detectar grupos de direcciones, que con un elevadísimo índice de certeza están controladas por una misma y única entidad. Esto engendra constelaciones de direcciones, muchas de las cuales pueden atribuirse a pertenecer a una entidad conocida (entrar aquí para más información). Muchas de nuestras métricas utilizan esta “capa de agrupación” extra. Se pueden encontrar muchos ejemplos en nuestro conjunto de “métricas ajustadas por entidades” (accede a nuestros documentos para ver la lista). Además de las causas ya mencionadas, también se presenta la siguiente situación:
- Agrupación de direcciones: Según se detectan constelaciones de nuevas direcciones, la información más reciente hace que sea necesario actualizar el histórico de datos al completo de una métrica, de esa forma podemos ofrecer la información del. blockchain más completa posible. A diferencia de todo lo que hemos cubierto hasta aquí, los registros temporales afectados sólo abarcan un corto intervalo. Como el agrupamiento de direcciones es un proceso automatizado y puede alterar constantemente nuestros datos, vamos a dedicar toda una sección a hablar de este asunto y desarrollar sus implicaciones en más detalle.
Métricas dedicadas a entidades individuales y categorías de entidades
Las métricas de este tipo engloban a las Métricas de los Exchanges, las Métricas Mineras, o la Oferta en WBTC de Custodios - resumiendo: métricas que describen entidades concretas o un conjunto de ellas. Para computar estas métricas, se necesitan grupos de direcciones cuyos dueños sean conocidos. Actualizamos periódicamente nuestro sistema de etiquetado utilizando una serie de técnicas, y en el caso de BTC el agrupamiento de datos respalda el proceso. Las causas que provocan cambios en los datos que ya hemos mencionado, pueden ocasionar los siguientes efectos:
- Listar entidades como fiables: Ofrecemos cobertura para esa entidad cuando consideramos que la calidad de la información que recabamos de un exchange o minero es lo suficientemente alta. No es algo que haga mutar estrictamente a las métricas, pero las opciones de filtro
agregadosí aparecerán diferentes (p.ej. cuando se quiera ver el balance total del conjunto de exchanges). Anunciamos cualquier cambio que se efectúe sobre las métricas de los mineros o exchanges en nuestros Registros. - Agregar manualmente nuevas etiquetas: A medida que vamos añadiendo nuevas etiquetas, nos enfrentamos al mismo reto que cuando se producen cambios por nuevas agrupaciones de datos: A veces puede que las métricas necesiten una recomputación de arriba abajo de su historial. Cuando activamos un nuevo grupo de etiquetas, de nuevo, lo anunciamos en el Registro.
Otros motivos de cambios en los datos
- Bugs y Cortes: Sólo somos personas y aunque no deba haber errores, pueden suceder. En rara ocasión debemos revisar o reparar alguna métrica, o tenemos problemas en la infraestructura de nuestro software. Dichos cambios se anuncian siempre en nuestros Registros.
- Metodología mejorada: Raramente tenemos que revisar la computación de una métrica. Sólo pasa cuando asumimos que la versión mejorada es más beneficiosa para el usuario o cuando su funcionamiento se asemeja más al de otras métricas, lo que permite que se comparen mejor entre sí. Una vez más, estas mejoras se comunican siempre en nuestros Registros.
La cruz del “agrupamiento de direcciones”
Cuando enumeramos las posibles causas que pueden alterar datos nos encontramos un caso particularmente interesante: El “agrupamiento de direcciones” con frecuencia requiere computaciones del historial completo y, al contrario de los anuncios esporádicos que aparecen en nuestros Registros, este es un proceso largo y constante. En esta sección vamos a profundizar en los detalles del “agrupamiento de direcciones”.
Nuestros algoritmos de agrupación y heurística aglutinan direcciones constantemente, siempre que sean controladas por la misma entidad única. En base a esta información, podemos p.ej. omitir cualquier cambio de volumen e inferir las transacciones reales del blockchain. A medida que pasa el tiempo, nuestra heurística detecta más y más conexiones entre direcciones, lo que eleva la calidad de aglutinamiento de direcciones (ver un ejemplo en la Fig. 11).
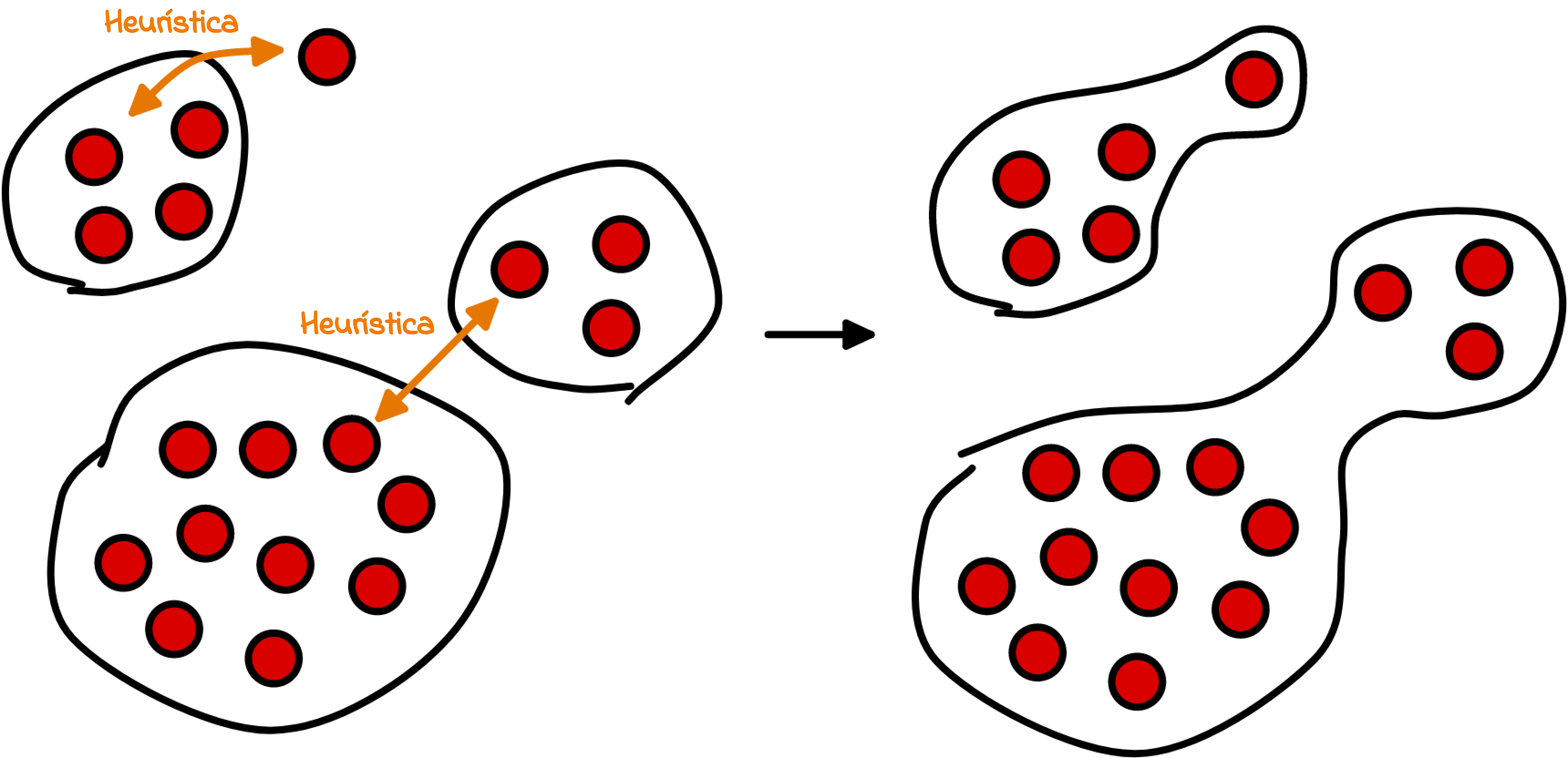
En Glassnode nuestra filosofía acerca de la agrupación de direcciones es utilizar un enfoque conservador que reduzca la cantidad de interconexiones erróneas entre carteras. Esto significa que cuando detectamos que se crean nuevas direcciones en el blockchain no solemos agregarlas inmediatamente a las constelaciones existentes, eso es algo que sólo pasa a medida que transcurre el tiempo y recabamos más información sobre esas direcciones.
Esto tiene varias consecuencias interesantes: Retomando el ejemplo anterior, una transacción inicialmente identificada como una transferencia entre dos partes diferentes puede de repente reconocerse como una simple transferencia interna, lo que modifica su contribución a todas las métricas relacionadas. Hemos hablado extensamente sobre cómo afecta este problema a las métricas de los exchanges en un artículo anterior.
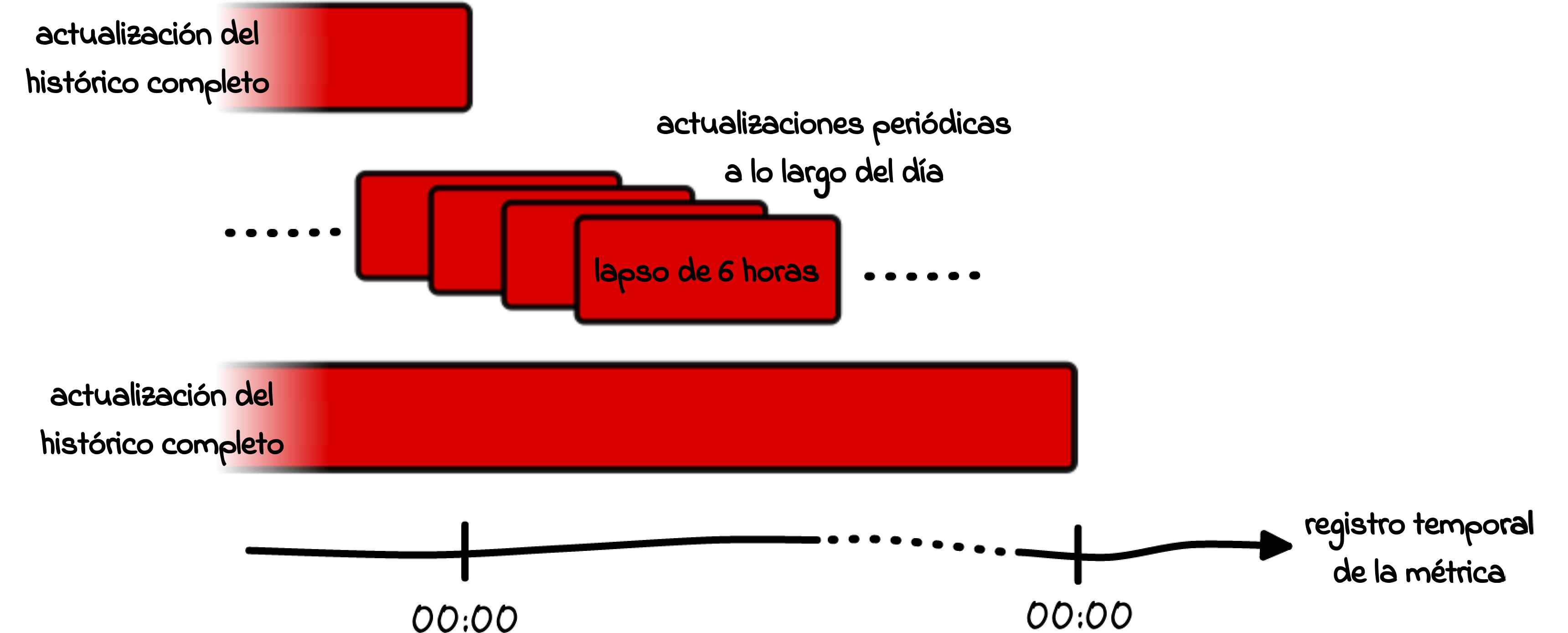
Para que nuestras métricas reflejen los datos de agrupación más actualizados, y por tanto muestren la cara más fiel del blockchain, se requiere también actualizar constantemente el registro histórico de la métrica. En la práctica es algo que conseguimos de dos maneras (ver la ilustración de la Fig.12):
- Computaciones diarias íntegras: Todas las métricas que utilizan datos de agrupación se recomputan una vez al día. Actualmente el proceso se desencadena a las 00:30 UTC y dependiendo de la complejidad y envergadura de la métrica, se termina de actualizar entre la 01:10 y las 02:40 UTC. Esto incluye a todas las resoluciones que ofrece una métrica.
- Actualizaciones periódicas: En el caso de las métricas con resolución de 1h o 10min recomputamos los valores de las últimas 6 horas en cada actualización. Por ejemplo, si nuestra actualización tiene lugar a las 10:00:00, no sólo añade los nuevos datos a la métrica, si no que implementa la información de agrupación recabada a todos los registros temporales entre las 04:00:00 y las 10:00:00. De esta manera se consigue que la nueva información entre en las métricas lo antes posible, sin esperar a que se realicen las actualizaciones diarias del historial completo.
La siguiente pregunta obvia es: ¿Cuánto tiempo tardan en coincidir los datos de una métrica? ¿Cuándo consideramos que los datos de agrupación son suficientes como para determinar que un valor es estable?
Convergencia de agrupación
Los efectos que tienen los nuevos datos de agrupación pueden ser muy diferentes según la métrica, aunque de acuerdo a nuestras observaciones podemos distinguir dos casos generales:
- Las métricas de agrupación basadas en actividad se infieren directamente de las transacciones que se producen en el blockchain durante el intervalo en cuestión. Algunos ejemplos incluyen el Número de Transacciones, el Volumen Entrante en un Exchange, o la Esperanza de Vida Media de las Monedas Gastadas.
- Las métricas de agrupación en base al estado del mercado por otra parte presentan fotogramas puntuales del blockchain. Las transacciones que ocurran dentro del intervalo pueden modificar ese estado, pero no lo definen per se. Por norma general: Para computar esta clase de métricas no sólo se tiene que tener en cuenta el intervalo de tiempo actual, si no también todos los anteriores. Ejemplos de ello son el Número de Ballenas, la cantidad de Oferta Líquida, o el Cambio Neto en las Posiciones de los Inversores a Largo Plazo.
Las métricas de agrupación que incluyen resoluciones de 1h y 10min pertenecen al primer grupo (a excepción del Balance de los Exchanges, el cual puede extraerse directamente de la propia actividad de los exchanges y puede por tanto considerarse como una de las métricas de actividad). Como hemos explicado, empleamos una ventana de seis horas para actualizar los valores más recientes de estas métricas. Al comparar las series temporales podemos cuantificar el lapso de cambio más común y estimar el marco temporal en que los datos convergen.
Nos gustaría idílicamente cuantificar esta convergencia con un método aplicable a todas las métricas, y estimar una cifra única para cada métrica. No obstante, como las métricas tienen características muy distintas y sus valores presentan distribuciones diferentes, parece que esto no es viable. Por ejemplo, obtener la diferencia entre los valores iniciales y los de convergencia resultaría en grandes desviaciones cuando la métrica oscila al rededor de cero.
Igualmente, usar los valores absolutos de las diferencias conduciría a conclusiones erróneas en métricas con grandes intervalos entre unos datos y otros. Por tanto nos decantamos por un enfoque más visual.
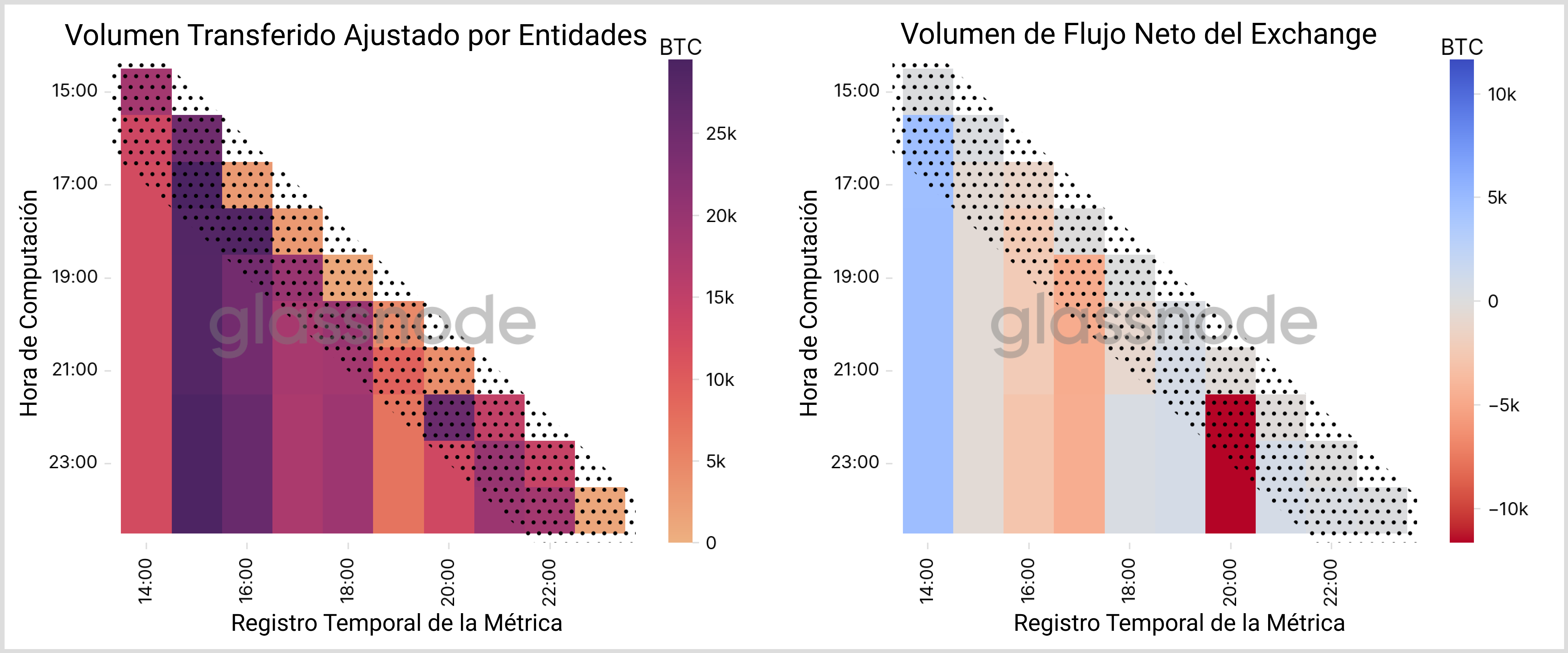
En la Fig. 13 presentamos dos métricas de ejemplo que emplean datos de agrupación con una resolución de 1h y muestra cómo varían los datos de la métrica tras cada computación subsiguiente. Es evidente que la información tiende a fluctuar dentro de las dos primeras horas después de haberse publicado, como se indica en las franjas punteadas. Después sin embargo, observamos que los valores se mantienen bastante constantes (“barras” verticales) y cualquier nuevo dato de agrupación adicional apenas tiene un leve efecto. De modo que podemos concluir que los datos de las métricas de agrupación basadas en actividad convergen típicamente en ~2 horas.
El motivo se puede explicar con el siguiente argumento: Todas las métricas que se basan en la actividad se pueblan con información proveniente de entidades con mucha actividad. Al mismo tiempo, una mayor actividad nos permite recabar más información estadística sobre las direcciones involucradas y aplicar con mayor frecuencia nuestra heurística, lo que a su vez produce datos de agrupación más completos para esas entidades con mucha actividad. Es por ello que los datos de estas métricas convergen con tanta rapidez.
Desafortunadamente, no podemos garantizar que las métricas que no se alimentan principalmente con datos de entidades con índices de actividad elevados converjan igual de rápido, como ocurre con varias métricas basadas en el estado del mercado, como veremos a continuación.
Convergencia de la Oferta Ilíquida - Estudio
Para ilustrar los problemas de convergencia de las métricas hemos elegido de ejemplo la Oferta Ilíquida. Se computa mediante la suma de los balances de todas las entidades que están por debajo de cierto umbral de liquidez. Para más detalles sobre esta métrica y su interpretación ver nuestro anterior artículo. En lo que respecta a la agrupación de direcciones nos topamos con el siguiente problema: Supongamos que detectamos una nueva dirección en el blockchain, la cual no envía ninguna de sus monedas durante mucho tiempo. Nuestro sistema de heurística podría no asignar esta dirección a una constelación existente - una constelación que en realidad puede presentar un comportamiento muy líquido y ser lo opuesto a esta métrica. Hasta que no se desplacen sus monedas, el balance de la dirección seguirá alimentando la oferta ilíquida y con ello sobrestimamos el valor real de la métrica.
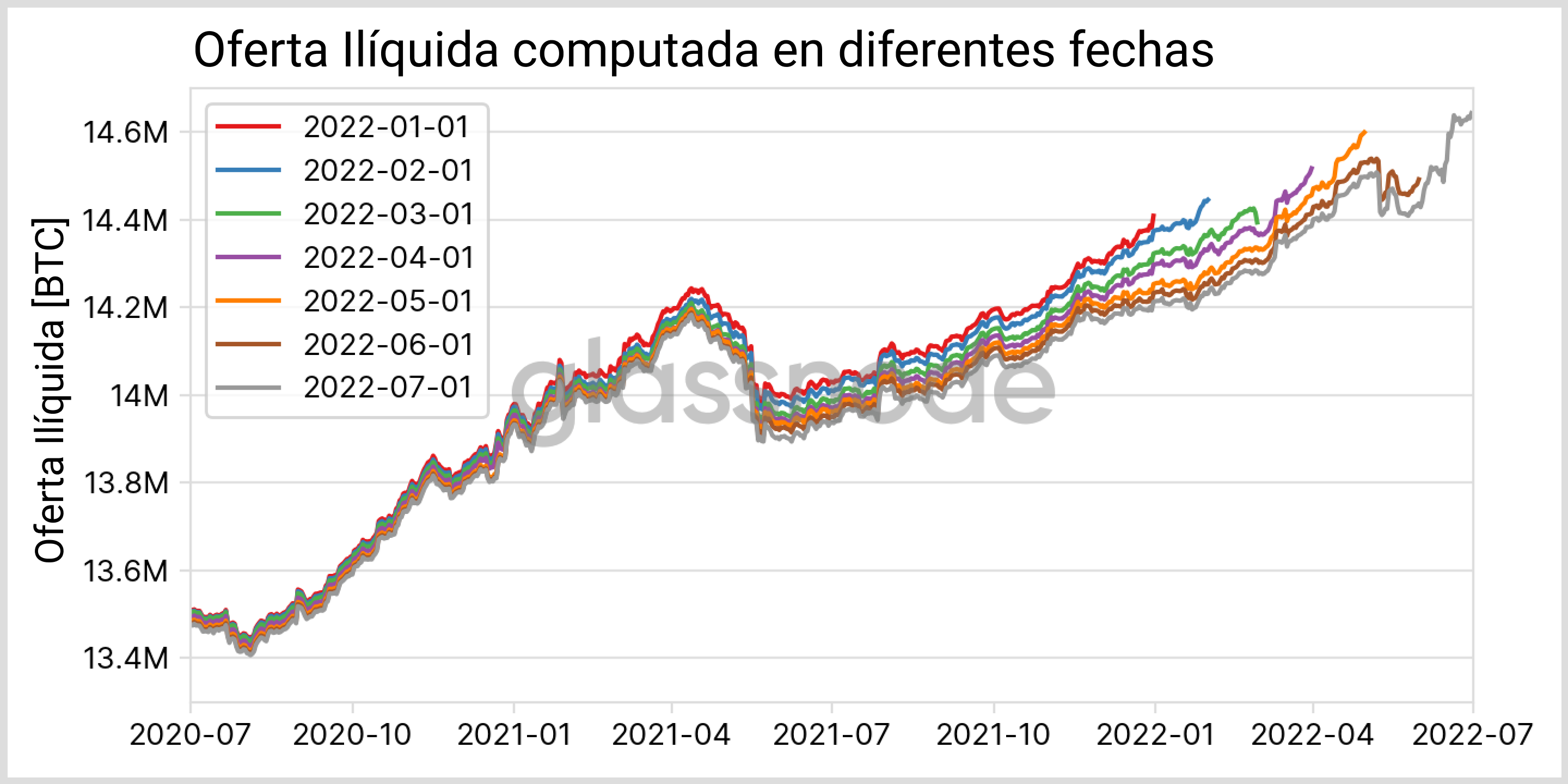
Para cuantificar este efecto podemos, por ejemplo, hacer una nueva comparativa entre los mismos datos computados en momentos diferentes, como muestra la Fig. 14. Mientras que los cambios relativos entre las actualizaciones consecutivas son prácticamente imperceptibles, con el tiempo terminan sumando mucho. Cuando comparamos la primera y última computación directamente en la Fig. 14, encontramos que los valores de los últimos ~30 días aún están sujetos a variar más de un uno por ciento. Willi Woo realizó un análisis parecido, donde concluyó que la mayoría de cambios tienen lugar dentro de los primero tres meses y que la convergencia total se consigue a los 4 años. A pesar de esta gran escala temporal y las modificaciones del día a día, los cambios generales que pueda sufrir la métrica pronto empiezan a ser estables - sólo que en valor absoluto las cifras aún no convergen.
¿Qué hacer con las métricas cambiantes?
Hemos hablado de varios factores que pueden provocar mutaciones en la información que contienen nuestras métricas. A continuación, queremos recomendar algunas maneras en que se puede lidiar con esta clase de cambios desde la perspectiva de un usuario.
Aspiramos a facilitar métricas con la mejor y más completa información posible, que es precisamente el motivo por el que nos esforzamos en actualizar las métricas constantemente. Pero como hemos podido descubrir, los datos históricos son por lo general los más estables, mientras que los registros más recientes están sujetos a cambiar con mayor asiduidad.
Si a alguien le interesa una métrica desde un punto de vista cualitativo, en términos generales no recomendamos usar los datos de las últimas dos horas para llegar a conclusiones demasiado firmes, ya que estos registros temporales pueden aún fluctuar enormemente. De hecho, para muchas de las métricas ajustadas por entidades, la resolución diaria es la más granular que ofrecemos a fin de factorizar este hecho, siempre que proceda. Incluso, si la métrica de interés no representa la actividad de una clase concreta de entidades, los valores absolutos deben cogerse con pinzas. Las tendencias a más largo plazo y las fluctuaciones del día a día, sin embargo, suelen ser estables.
La situación cambia si se usan las métricas con un propósito cuantitativo, como puede ser el trading o el aprendizaje automatizado. Debido a las actualizaciones que efectuamos al histórico de nuestras métricas que usan datos de agrupación, se debe anticipar una cierta holgura en la información que contienen por las futuras modificaciones que vayan a sufrir los datos con registros temporales más antiguos. Esto causa ajustes de anticipación imparciales, denominados como uno de los “Siete pecados de la inversión cuantitativa” de Y. Luo et al. Una cita de su trabajo dice, “debemos utilizar siempre datos impuntuales para hacer backtesting”.
Información Inmutable: Llegan las métricas impuntuales
Datos impuntuales (DI) quiere decir una instantánea tomada en un momento en particular, sin que se revise esa información a futuro. En el contexto de las métricas, quiere decir que los datos se congelan en el momento de su publicación y no se modifican nunca - sin importar lo que contengan los siguientes bloques o cuánto mejoren nuestros conocimientos de agrupación. Esta manera de actualizar diferente está representada en la Fig. 15.
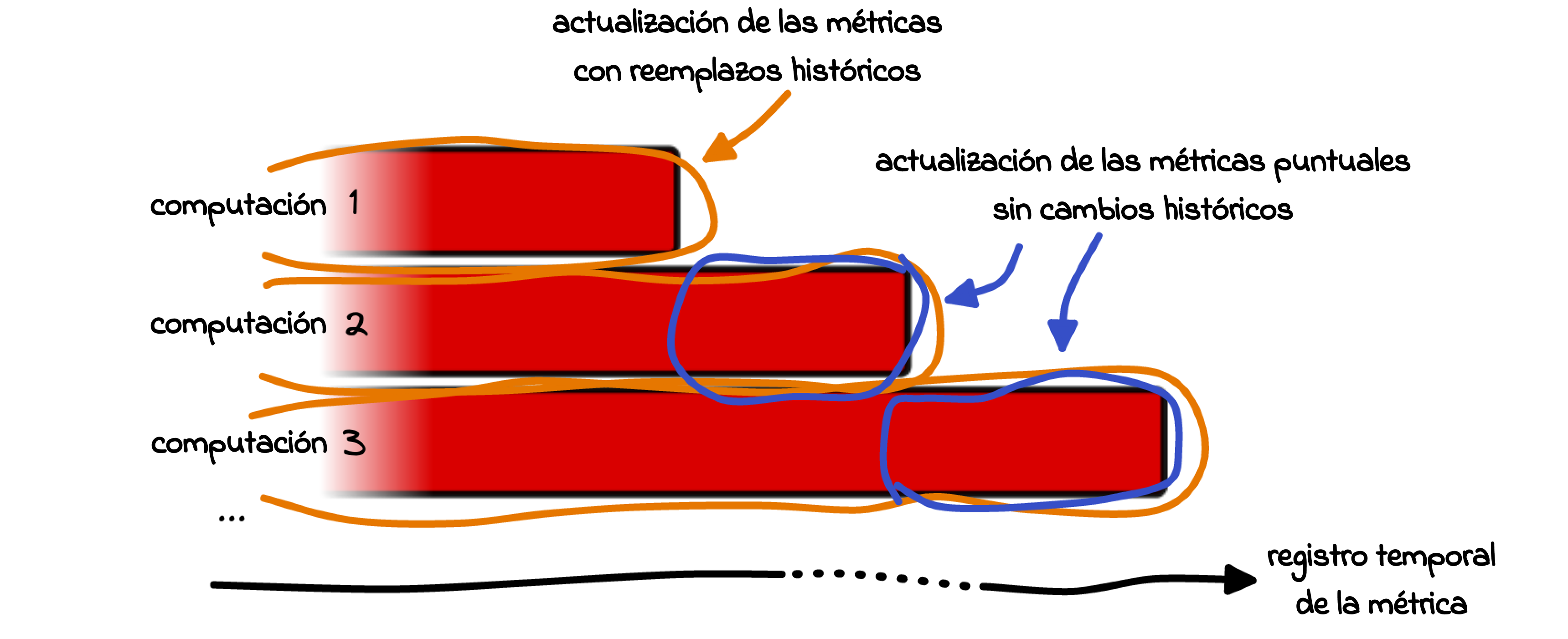
Siempre ha sido posible crear esta clase de métricas con historiales inmutables, sólo hay que recabar periódicamente la información de nuestra API y guardar cada nuevo dato tal cual viene. Sin embargo, este proceso requería un proceso manual por separado para cada usuario y eso incrementaría los costes. Por eso nos alegramos de poder ampliar nuestra oferta API para incluir un gran conjunto de “Métricas Impuntuales” desde hoy mismo.
Nuestras nuevas métricas con DI ofrecen información inmutable en el sentido de que cada nuevo dato únicamente se anexiona y no cambia. Como es natural, no representan necesariamente los datos más refinados que tenemos acerca del blockchain - esos datos más pulidos siguen estando siempre disponibles a través del elenco de métricas (mutables). En la Fig. 16 se puede ver una comparativa entre nuestras métricas existentes y las nuevas con datos impuntuales.
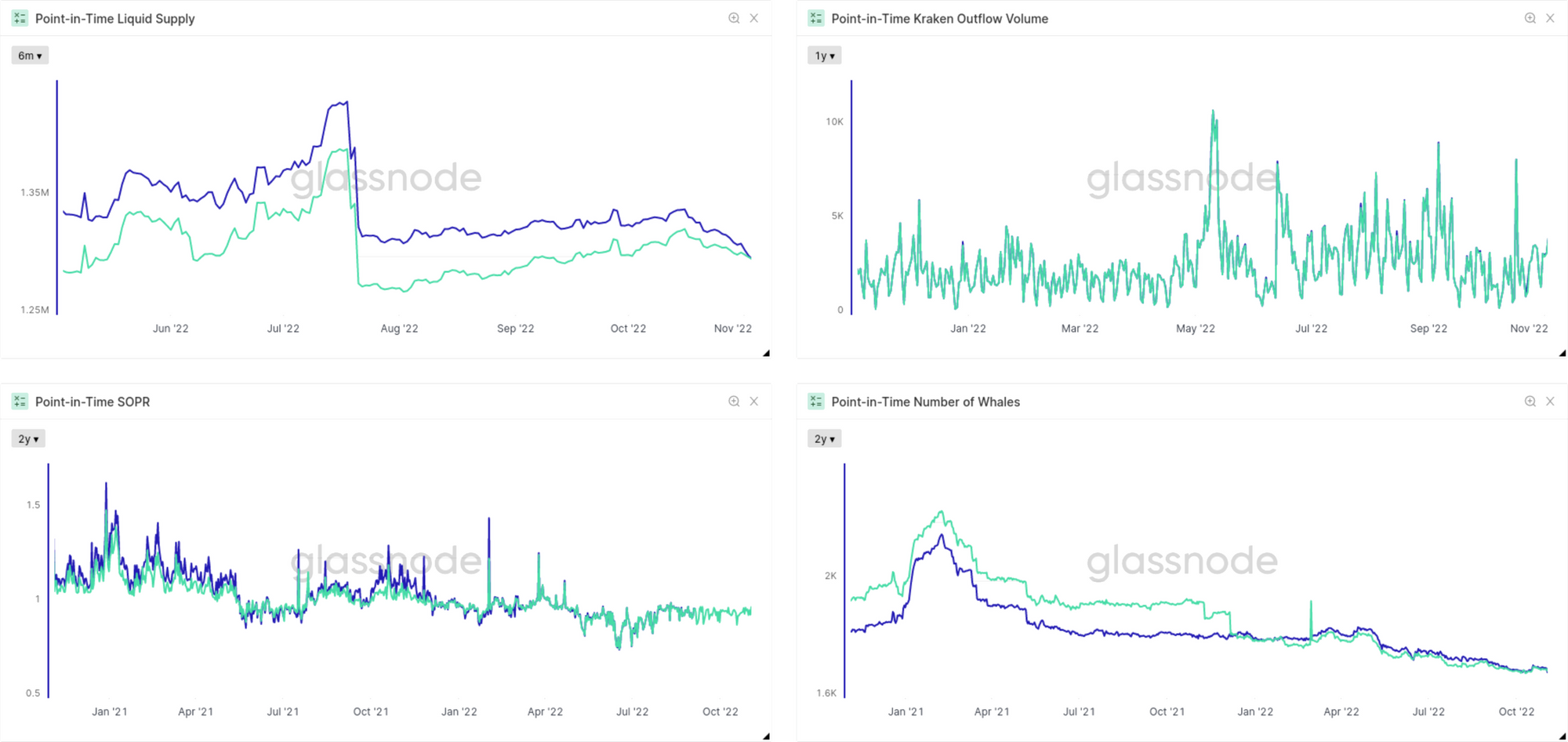
En la sección de la Mutabilidad de la Información hemos aprendido que las “métricas basadas en el estado del mercado” son más susceptibles a modificar sus registros históricos que las métricas basadas en “actividad”. Exactamente lo mismo ocurre cuando comparamos las métricas mutables con las que usan datos impuntuales: Las métricas basadas en actividad se solapan más (dentro del típico estándar de variación de una métrica), mientras que las basadas en el estado del mercado con el tiempo suelen presentar mayores discrepancias.
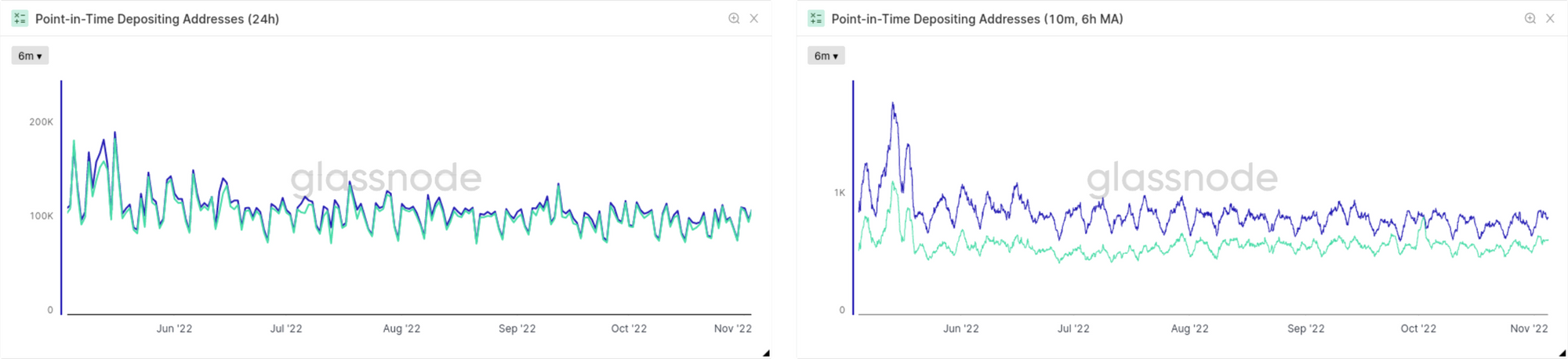
Otro aspecto interesante del que nos podemos beneficiar con las métricas impuntuales es su manera de comportarse en diferentes resoluciones. En la Fig.17 vemos como ejemplo el número de Direcciones Depositantes en los Exchanges. En todo momento la versión impuntual infravalora los datos que más tarde se obtienen con los mecanismos de agrupación y etiquetado, pero las discrepancias son mucho mayores cuando utilizamos la resolución de 10 minutos de las métricas. Es algo que se puede explicar fácilmente: Cuando se computa el primer valor del primer dato en la resolución de 24h, la mayoría de bloques que contribuyen a esa franja informativa sobrepasan con creces las 2 horas de edad, que es precisamente el marco temporal que establecimos anteriormente para cuantificar el punto de convergencia de las métricas basadas en actividad. Por consiguiente, los valores generales que se obtienen de las métricas impuntuales también se acercan a esos niveles de convergencia. En cambio, en las resoluciones superiores casi ninguno de los bloques incluidos tienen aún la madurez requerida cuando congelamos sus datos en la versión impuntual de las métricas.
Resumen y Conclusiones
Hemos hablado de los diferentes factores que se ven influenciados cuando una métrica es actualizada y calculado la distribución de los retrasos esperados. Asimismo, hemos considerado los diferentes factores que hacen necesario actualizar los valores de una métrica más allá de los últimos registros temporales impresos. En particular, hemos visto que la agrupación de direcciones y el etiquetado manual conllevan recomputaciones completas del histórico de una métrica. Esas actualizaciones históricas se aseguran de que la información incorpora el conocimiento más refinado que tenemos sobre el blockchain, pero pueden conllevar importantes ajustes de anticipación imparciales. Para solucionar este problema, hemos presentado un conjunto de métricas con datos impuntuales en las que todos su datos históricos permanecen inmutables, lo que las convierte en perfectas candidatas para ser utilizadas en el campo del backtesting y otros relacionados.